나만의 원피스 루피 챗봇 만들기 with HyperClovaX
Hyper CLOVA 스터디를 참여하게 되었다🙇이직준비와 이직 신입 적응기를 거치며 5월은 빠르게 흘러갔다. 매번 일을 벌이는 걸 좋아하는 나에게 찾아온 트리거 같은 역할 풀잎스쿨네이버클라우드
hyun941213.tistory.com
위 글을 시작으로 하이퍼크로버로 LLM을 여러 가지 시도를 많이 해봤던 것 같습니다. 여러 스터디도 진행하고 있고 최근에는 하이퍼크로버 막차 타기 Study의 모각코에 다녀왔습니다. 거의 제출하기 전 모여서 아이디어를 나누고 서로의 Insight도 나누고, 네트워킹을 하는 자리였습니다. 아무래도 막차 탑승이라는 주제이고, 누구나 스터디를 할 수 있다는 점에서 다양한 연령 인원 배경들이 있었습니다.

계속 루피를 업그레이드 하는 과정에서 다양한 하이퍼크로버의 기능들을 사용을 해봤었고, 이제 내가 잘할 수 있는 RAG를 붙여보자였습니다. 일단 기간이나 프로젝트의 규모 또한 RAG를 Conventional RAG 인 navie RAG 정도만 구축하면 될 거라고 생각했습니다. 추후 LangGraph 나 Agent를 활용해서 고도화할 생각입니다.
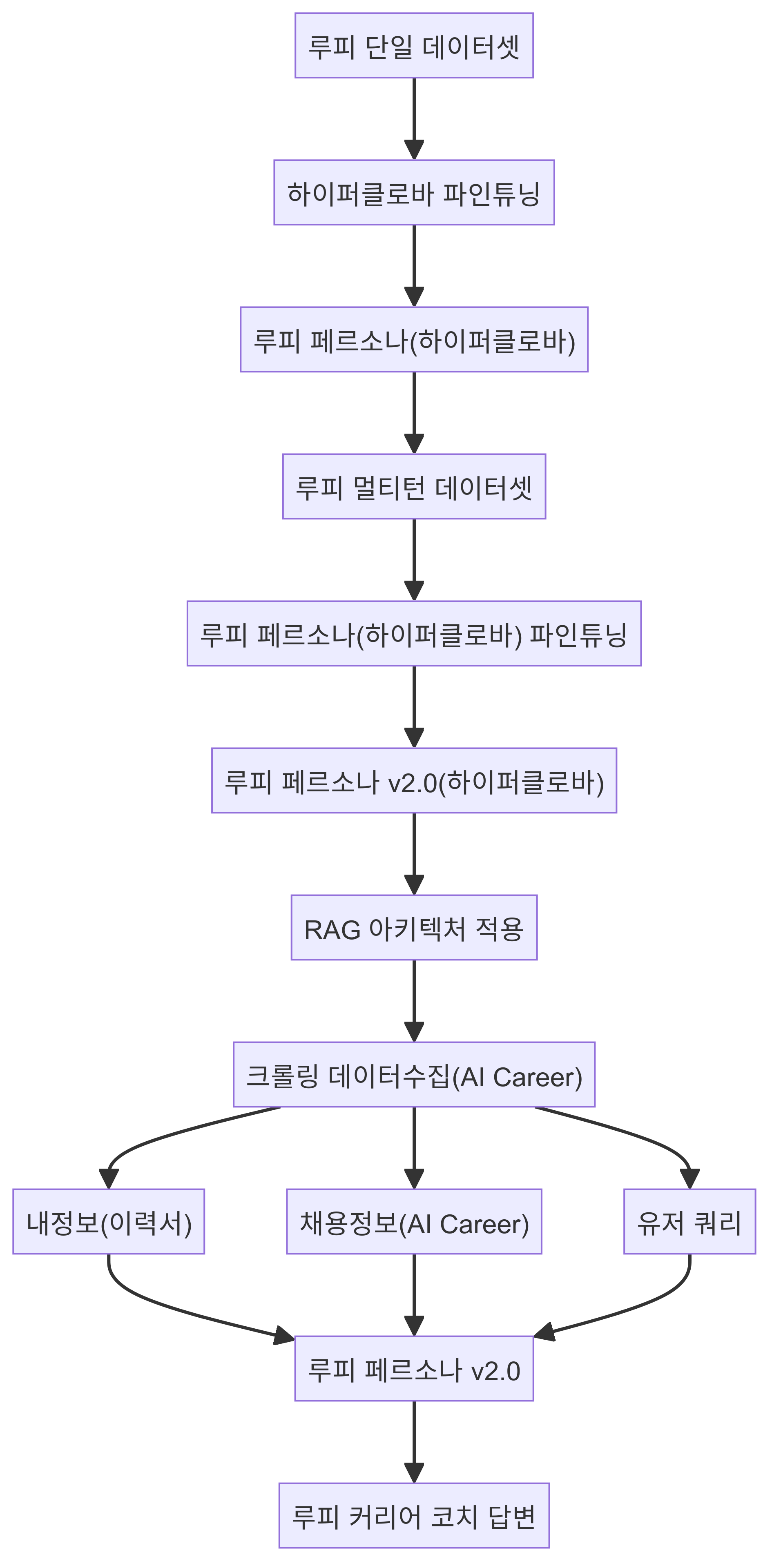
현재 프로젝트가 수행중인 다이어그램 맵입니다. RAG 아키텍처는 제일 간단한 faiss Vector DB로 구성을 하고, bm25 keyword 기반의 두 개를 같이 사용하는 앙상블 레트리버 기반의 Hybrid Search를 사용했습니다. 임베딩 모델은 Huggingface의 BAAI/bge-m3 모델을 활용하고 mps 맥북기반 설정을 적용하였습니다. BM 25에서는 아무래도 형태소 추출기가 중요하다고 판단해서 preprocess_function을 kiwi를 활용해서 토크나이징 하는 방식을 채택해서 키워드기반의 추출의 성능이 올라갈 수 있도록 구성을 하였습니다. 매우 간단한 로직이라고 볼 수 있으나 Core기술만 신기술(트렌드)을 적용해 봤습니다.
def process_documents(loader):
documents = loader.load()
st.write(f"Loaded {len(documents)} documents from the uploaded file")
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100, length_function=len, is_separator_regex=False)
docs = text_splitter.split_documents(documents)
st.write(f"Split the documents into {len(docs)} chunks")
return documents, docs
def initialize_retrievers(documents, docs):
try:
hf = HuggingFaceEmbeddings(model_name="BAAI/bge-m3", model_kwargs={"device": "mps"})
db = FAISS.from_documents(docs, hf)
bm25_retriever = BM25Retriever.from_texts([doc.page_content for doc in docs], metadatas=[{"source": 1}] * len(docs), preprocess_func=kiwi_tokenize)
bm25_retriever.k = 2
faiss_retriever = db.as_retriever(search_kwargs={"k": 2})
ensemble_retriever = EnsembleRetriever(retrievers=[bm25_retriever, faiss_retriever], weights=[0.7, 0.3])
7:3 비율로 앙상블을 해주게 됩니다. semantic search 에서도 "MMR", "Similarity_search" 등 다양한 방법도 Dense Vector에서 사용할 수 있습니다. 이 점은 랭체인 노트에서 참고해 주시면 좋을 듯합니다. 저는 MMR 기반의 Vector Search를 사용했습니다.
02. FAISS
.custom { background-color: #008d8d; color: white; padding: 0.25em 0.5…
wikidocs.net
Streamlit으로 UI는 간단하게 구성을 하였습니다. 시작하면 크롤링을 해오기 때문에 일정 시간이 걸립니다.


일상적인 루피의 답변만 나오게 됩니다. 현재 세션 상태에는 크롤링 코드가 있지만, 토큰낭비를 줄이기 위해 PDF 정보를 넣은 후 세션이 활성화되게끔 구성하였습니다. PDF를 넣으면 세션이 활성화가 되고 , AI Career의 최상단의 공고를 Context로 가져오게 됩니다. AI CINAMON의 채용정보를 알게 됩니다.
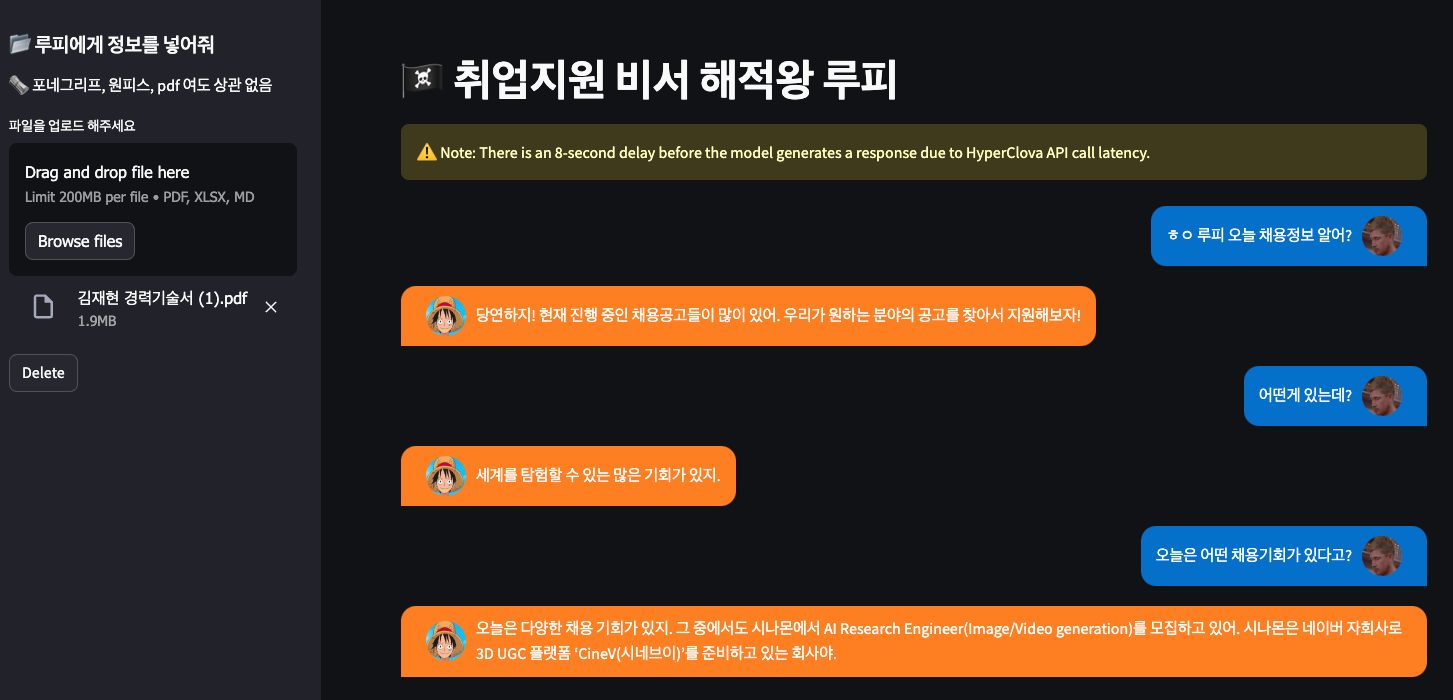
side bar 옆에는 pdf 형태로 이력서를 넣을 수 있고 위 이력서는 RAG 파이프라인을 거쳐서 chunk, embedding, Vector store 저장이 이루어집니다.
RAG_PROMPT_TEMPLATE = """
#질문 : {question}
#정보 : {context}
#채용공고 :
{data}
#답변 : """
그 후 이제는 위 prompt template 를 거쳐서 지시사항들과 함께 하이퍼크로버에게 인퍼런스가 되는 형태입니다. 이 과정을 자주 사용하면서 느낀 건 HCX-003 이 아직은 ICL 이 많이 약하구나 하는 느낌이었습니다. 지시사항만 명확히 넣어준다면 GPT-4에서는 어느 정도 제가 원하는 Output을 가져왔던 반면에 하이퍼크로버는 다양한 로직으로 예외처리를 해주어야 할 듯 한 느낌이었습니다.

저는 이미지 경력은 없지만 경력기술서에 다양한 CV 프로젝트 경험과 딥러닝 프레임워크 경험을 적어놓았기 떄문에 위를 토대로 답변을 해주는 모습입니다. 루피가 '내" , "내가"로 마치 내 이력서인데 자기처럼 답변하는 이유는 구성당시에 내가 해적왕이다 내가 바로 루피다 와 같이 답변자체를 내가 , 내로 구성을 많이 했기 때문에 그에 따른 영향인 듯합니다. 이 부분도 수정을 해주어야 할 듯합니다.

Streamlit 단락 에러로 인해 위처럼 나오긴 하지만 디퓨저 공부를 위한 공부법도 알려줍니다.

일반적인 면접을 가기 위한 질문도 답변을 잘해주는 모습입니다.


실제 복지에 대해서 물어봐도 잘 답변해 주는 모습입니다. Context에 제대로 들어가서 잘 답변을 하는 모습이라고 볼 수 있습니다.
위처럼 langchain과 연동에 RAG는 잘 구축이 되어있습니다. 그러나 Session 상태라던지 현재 로직은 ICL 이 약할 수 있는 하이퍼크로버에게는 쥐약이라고 판단이 되는 것이, 계속 크롤링 정보와, 내 PDF 정보가 같이 Context에 같이 호출이 되어 질문을 하게 됩니다. 이 부분을 수정을 해야 한다고 판단을 하였고, 일단 물리적인 Delete 버튼을 통해서 세션을 다운시켜서 일상 대화가 가능하도록 하게 만들었습니다. 또한 토큰의 한계를 극복하기 위해 LLM Chaining 코드를 만들어둔 상태입니다. 크롤링 상태정보를 하이퍼크로버가 긴 글을 요약해서 채용정보의 핵심정보를 토대로 여러 채용정보를 Context로 주기 위한 작업을 준비하고 있습니다.
job_chain = jobsummary_prompt | llm | StrOutputParser()
RAG_PROMPT_TEMPLATE = """
#질문 : {question}
#정보 : {context}
#채용공고 :
{jobchain}
#답변 : """
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| RAG_PROMPT_TEMPLATE
| llm
| StrOutputParser()
)
이 부분은 LangGraph를 통해 쿼리가 들어오면 레트리버 할지 안 할지 맞는지 안 맞는지 자가수정 RAG 기법을 통해 보완이 가능해 보이긴 합니다. 물론 제 소프트엔지니어링 지식이 얕아서 못하는 것 일 수도 있지만.. 우선 그 점을 나중에 수정해보려고 합니다. 그 부분만 보완이 된다면 하이퍼크로버 자체도 다시 튜닝을 해보면서 내가 , 내로 시작하는 것도 없애보며, 다양한 방법을 통해 고도화를 시켜볼 수 있지 않을까 싶습니다.
'NLP' 카테고리의 다른 글
| 나혼자 만드는 금융권 LLM Assistant - (1) 페르소나 모델 만들기 (1) | 2024.07.19 |
|---|---|
| HyperClova X 에 LangGraph 적용하기 A to Z (0) | 2024.07.09 |
| RAG 시스템 을 구축하기 위한 데이터 전처리 - PDF (0) | 2024.06.25 |
| HyperClova X 를 Sliding Window 활용하기 - 루피챗 기억 넣기 (0) | 2024.06.21 |
| LangChain 을 활용한 Custom LLM 사용하기 (with HyperClova X) (0) | 2024.06.20 |



