다들 Navie RAG로 간단하게 ChatPDF의 형태로, PDF를 데이터로 집어넣고 청크 하고, 임베딩해서 벡터스토어에 넣고 레트리버를 만들어주고 쿼리가 들어오면 임베딩 해서 다시 벡터스토어에서 벡터서치를 통해 document의 page_content를 받아와서 prompt를 넣어주는 일련의 과정을 경험해 봤을 것입니다.

RAG survey 에선 이 과정을 더 넘어 Advanced RAG 를 통해 RAG 성능을 극대화해야 한다 하고, 다양한 방법론들을 소개합니다.
RAG 어떻게 하면 더 잘 할까?
RAG(Retrieval-Augmented Generation)는 LLM(Large Language Model)의 출력을 최적화하여 응답을 생성하기 전에 학습 데이터 소스 외부의 신뢰할 수 있는 knoledge data를 참조하도록 하는 Process입니다. LLM 은 방대한
hyun941213.tistory.com
저도 RAG를 잘하기 위한 방법들을 쭉 생각을 해본적이 있었는데요. 물론 이것들이 도움이 안될리는 없습니다. HyDE, Reranking 등 다양한 방법론을 통해서 하이라키 속에서 해법을 찾으려고 할텐데요. 또한 이것들은 매우 유기적으로 연결이 되어있기 때문에 navie RAG 랑 동일하게 역시나 한번 잘못 뽑으면 계속 잘못 뽑을 가능성이 높습니다. 그래서 Modular RAG 하나의 에이전트의 형태로, 상호보완을 하는 형태의 RAG 들이 많이 연구도 사실 되고 있는데요. 저는 그냥 문득 애초에 Data 를 잘 넣어주면 되자나? 라는 생각이 있었습니다. 물론 그것은 방대한 enterprise 급에서는 현실적으로 어려운일인데요. 그냥 우리가 시도하는 토의프로젝트 수준에서는 가능하지 않나? 란 생각이 들었습니다. RAG 를 쓰는 목적은 1차적으로 검색증강 즉 언어모델에게 정보를 주어서 할루시네이션을 개선하기 위함입니다. 곰곰이 루피봇에 RAG를 붙이다가 생각을 해보았습니다. 아는 분들도 물론 많겠지만 PDF를 처리하는 방법을 공유해 봅니다.
1. Vision Langauge Model을 활용해 보자.
최근에 나온 GPT-4o를 활용하는 방법입니다. 물론 돈은 많이 들 수 있습니다. 그러나 Critical Point 가 있는 소량의 자료에선 큰 활용을 할 수 있다고 생각합니다.
https://openai.com/index/openai-api/
OpenAI API 가이드를 활용하시길 추천드립니다. VQA 특징처럼 모델에게 input으로 이미지와 결과를 받고 싶기 위한 질의의 쿼리를 날립니다. GPT 내부에서 VLM을 통해서 어떤 원리로 돌아가는지는 정확히 모르겠지만, text OCR을 어느 정도 해주는 것 같습니다.
import base64
import requests
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
def get_image_content(api_key, image_path):
base64_image = encode_image(image_path)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "위 이미지에 대한 내용을 출력하고, markdown 형식으로 출력하세요. (표 내용을 포함)"
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
}
]
}
],
"max_tokens": 4096
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
response_data = response.json()
content = response_data['choices'][0]['message']['content']
return content
# OpenAI API Key
api_key = "your api key"
# Path to your image
image_path = "your img path"
# Get and print the content of the image
print(get_image_content(api_key, image_path))
위와 같이 코드를 구성해 주면 base64를 통해 이미지를 거쳐서 text로 결과를 받아 볼 수 있습니다. GPT-4o의 가격은 다음과 같습니다.
결과
위와 같이 markdown의 형태로 response를 받아볼 수 있습니다. markdown으로 리턴값을 받는 이유는 언어모델이 보통 github의 문서도 readme 도 학습이 많이 되었을 뿐만 아니라, markdown 형태의 학습량이 언어 중에 제일 많다는 기록을 본 적이 있었습니다. 그때부터 저는 이전 회사에서 전처리를 할 때 마크다운으로 바꿔서 했던 편입니다.
가장 강력할 수 있는 방법이지만 vision task를 활용해야 하기 때문에 과금이 든 다는 부분이 있습니다 critical point를 찾아서 쓰는 것이 적당하다 볼 수 있습니다.
2. PDF 라이브러리들을 활용해 보기
import glob
pdf_files = glob.glob('*.pdf')
for pdf_file in pdf_files:
print(pdf_file)
with pdfplumber.open(pdf_file) as pdf:
for i in range(len(pdf.pages)):
page = pdf.pages[i]
image = page.to_image()
image.save(f'{pdf_file}_page_{i}.png', format='PNG')
print(f'{pdf_file}_page_{i}.png')
위 코드를 활용해서 로드 후 이미지를 저장 처리를 해줍니다.
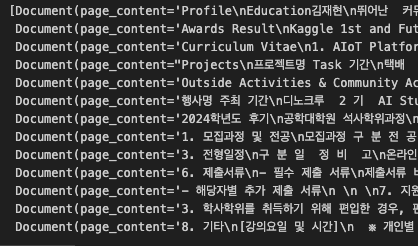
pypdf 관련 라이브러리들을 데이터를 로드해 보면 보통 이런 형태로 page_content에 본문내용이 들어있고, metadata에 docs에 관련된 정보가 더 들어있습니다.
machine-learning/random/extracting_text_from_pdf.ipynb at main · patchy631/machine-learning
Contribute to patchy631/machine-learning development by creating an account on GitHub.
github.com
위 코드를 토대로 실험을 해보았습니다. 현재 보니깐 langchain에서도 지원하는 라이브러리입니다.
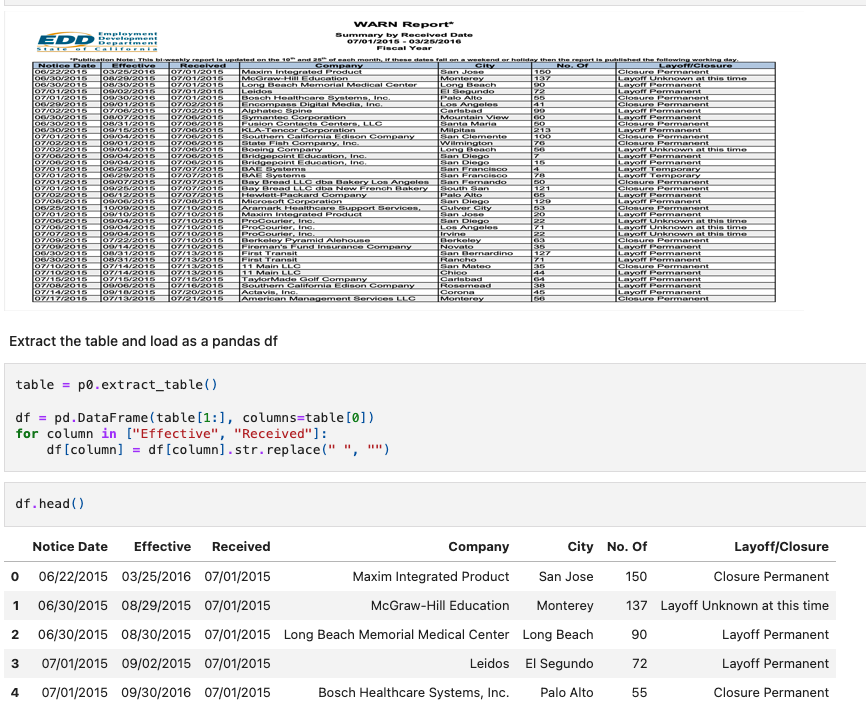
이미지를 따로 저장한 후 그 이미지에서 테이블을 추출하는 형식입니다. 그 후 입맛에 맞게 데이터프레임이니 to_markdown 형태로 저장을 해서 언어모델에게 전달을 해도 되고. csv로 저장해서 따로 docs 로드를 통해 정보를 로드할 수도 있습니다. 그러나 위 task의 문제는 표만 output으로 나오기 때문에 데이터가 많은 경우나 데이터에 관한 명시가 없는 경우 할루시네이션을 유발합니다. 그래서, 적절한 metadata tagging을 해주어야 하는 번거로움이 있을 수 있습니다. 예로 들어 보통의 PDF load에서 단락별로 구성을 한다고 가장했을 때 그 단락에 대한 집계표 이런 식으로 metadata를 주는 경우 매우 효과적인 방법이라 볼 수 있습니다.
코드
import glob
import pdfplumber
import pandas as pd
from langchain_community.document_loaders import PyPDFLoader
from langchain.schema import Document
pdf_files = glob.glob('*.pdf')
pages = []
for pdf_file in pdf_files:
loader = PyPDFLoader(pdf_file)
pages.extend(loader.load_and_split())
extracted_tables = {}
for pdf_file in pdf_files:
with pdfplumber.open(pdf_file) as pdf:
for i in range(len(pdf.pages)):
page = pdf.pages[i]
image = page.to_image()
image_path = f'{pdf_file}_page_{i}.png'
image.save(image_path, format='PNG')
table = page.extract_table()
if table is not None:
df = pd.DataFrame(table[1:], columns=table[0])
markdown_table = df.to_markdown()
extracted_tables[(pdf_file, i)] = markdown_table
else:
extracted_tables[(pdf_file, i)] = "No table found"
for page in pages:
pdf_file = page.metadata['source']
page_number = page.metadata['page']
if (pdf_file, page_number) in extracted_tables:
table_content = extracted_tables[(pdf_file, page_number)]
page_content = page.page_content
updated_content = f"{page_content}\n\nTable extracted from page {page_number}:\n{table_content}"
page.page_content = updated_content
for page in pages:
print(f"Document Source: {page.metadata['source']}")
print(f"Page Number: {page.metadata['page']}")
print(f"Page Content:\n{page.page_content}\n")
print("---------------------------------------------------\n")
위 코드처럼 구성을 해줍니다. 반복문이 돌면서 사진을 먼저 저장해 주고 그 후 사진에서 표가 있는 내용이 있다면 추출한 후 그 내용이 있는 docs content에 저장하는 코드입니다.

docs로 구성된 첫 번째 장 페이지는, 표가 없기 때문에 그냥 일반내용이 출력되었고 표가 있는 1장의 내용은 마크다운이 같이 첨부가 되어서 나오는 모습을 볼 수 있습니다. 그렇다면 이제 위 내용을 가지고 LLM에게 질의를 던지는 것이 가능해집니다. 아마 중복되는 내용이기 때문에 LLM 이 데이터 안에서 meta tag의 다른 정보 없이 해당내용을 맵핑해서 추론을 해줄 것으로 생각이 듭니다.
이런 식으로 쓸 수는 있지만 이 방법에도 단점은 불필요한 token의 낭비가 어쩌면 큰 단점이라 볼 수가 있습니다. 그렇기 때문에 대용량의 데이터는 그만큼 위험이 있을 수 있습니다 Chunk 단위에서 잘리는 부분이 있기 때문에 이 방법 또한 meta tag부분을 확실히 해주는 게 keypoint라고 할 수 있습니다.
그렇다면 meta tagging 은 어떻게 할 수 있을까? 아래처럼 코드를 구성해서 라벨링을 해봅니다.
https://teddylee777.github.io/langchain/metadata-tagger/
자동화된 메타데이터 태깅으로 문서의 메타데이터(metadata) 생성 및 자동 라벨링
문서 관리를 위한 메타데이터 태깅은 필수적이지만 번거로울 수 있습니다. OpenAI 기반의 자동화된 메타데이터 태깅 방법을 통해 이 과정을 효율적으로 만드는 방법을 알아봅시다.
teddylee777.github.io
- 테디노트 경록님의 메타데이터 태깅 글을 보고 참고하였습니다.
from typing import List, Optional
import json
from pydantic import BaseModel, Field
from langchain import hub
from langchain.llms import OpenAI
from langchain.chains import create_metadata_tagger
from PyPDF2 import PdfFileReader
import os
# Define the properties to extract for movie-related keywords
class Properties(BaseModel):
# Keywords
keyword: List[str] = Field(description="Several keywords extracted from the document related to movies")
# Table features
table_features: Optional[List[str]] = Field(description="Features of the table extracted from the document")
# Table content
table_content: Optional[List[str]] = Field(description="Content of the table extracted from the document")
# Create the metadata tagger
document_transformer = create_metadata_tagger(
Properties, # Properties to extract
OpenAI(temperature=0, model="gpt-3.5-turbo"), # OpenAI model
)
# Function to extract text from PDF
def extract_text_from_pdf(pdf_path):
pdf = PdfFileReader(open(pdf_path, "rb"))
text = ""
for page_num in range(pdf.getNumPages()):
page = pdf.getPage(page_num)
text += page.extractText()
return text
# Load PDF content
pdf_path = "path/to/your/pdf/file.pdf"
pdf_content = extract_text_from_pdf(pdf_path)
# Simulating splitting of content into chunks for tagging (you can define your own logic)
data = [{"page_content": chunk} for chunk in pdf_content.split("\n\n")]
# Pull the prompt
prompt = hub.pull("teddynote/metadata-tagger")
# Tag metadata for the first 5 chunks
enhanced_documents = document_transformer.transform_documents(data[:5], prompt=prompt)
# Print the tagged content with metadata
for d in enhanced_documents:
print(d.page_content + "\n\n" + json.dumps(d.metadata, ensure_ascii=False))
print("\n---------------\n\n")
위처럼 우리 코드를 적용만 하면 됩니다. 그럼 docs 단위에서 메타 데이터 태깅을 할 수 있고 이 데이터 정보를 토대로, 레트리버를 한다면 더 좋은 성능의 결과를 얻을 수 있을 것이라고 판단됩니다. pdf 로드한 후 이미지 처리 후 표를 추출하고 그 데이터를 다시 metadata-tagger를 기준으로 라벨링을 해주는 로직입니다.
오늘은 pdf를 전처리하는 방법을 나름 생각해 보다가 정리를 해보았습니다. 다들 많은 insight가 되고 더 많은 방법들이 나오고 공유되었으면 합니다. 감사합니다.
+
teddy note 님의 PDF 관련 QnA 에 좋은 내용들이 많습니다 참고하시고 본인이 해결하고자하는 Task 를 해결해보세요.
fitz 사의 pyMUPDF 등 다양한 내용을 소개해주셔서 더 많은 인사이트를 얻을 수 있었습니다. 잘 합쳐서 하나의 형태로 정리해볼 예정입니다.
'NLP' 카테고리의 다른 글
| HyperClova X 에 LangGraph 적용하기 A to Z (0) | 2024.07.09 |
|---|---|
| HyperClova X 를 통한 RAG 기반 이력서 비서 (0) | 2024.07.01 |
| HyperClova X 를 Sliding Window 활용하기 - 루피챗 기억 넣기 (0) | 2024.06.21 |
| LangChain 을 활용한 Custom LLM 사용하기 (with HyperClova X) (0) | 2024.06.20 |
| HyperClovaX에 2024 미쉐린 음식점을 학습시키자! (1) | 2024.06.19 |



