HyperClova X 를 통한 RAG 기반 이력서 비서
나만의 원피스 루피 챗봇 만들기 with HyperClovaXHyper CLOVA 스터디를 참여하게 되었다🙇이직준비와 이직 신입 적응기를 거치며 5월은 빠르게 흘러갔다. 매번 일을 벌이는 걸 좋아하는 나에게 찾아온
hyun941213.tistory.com
AI 막차 타기 이후 하이퍼크로버에 적용할게 뭐가 없을까 생각해 보다가 LangGraph를 적용해 보자 생각이 들었습니다. 예전에 CRAG 논문 읽고 코드 구현 examples로 코드를 실행해 본 기억이 있었는데요. 그때 Github에 공개키로 올려서 150$이 삭제당한 적이 있어서 그 이후 랭그래프 쳐다도 안 보고 있다가 LangChain 밋업 코리아 테디노트님 연사를 유튜브에서 보고, 아 이거 해야겠구나 생각이 들었습니다. 사실 그땐 코드를 그냥 돌리기만 했고, ipynb 파일이 너무 길길래 그냥 보기 싫었는데 이번엔 경록님의 설명을 들으면서 하니깐 이래서 이렇게 구성하는 거구나 하면서 코드를 적용했습니다.
랭체인계의 1타 강사라고 해도 손색이 없는 테디노트님의 강의를 적극 추천드립니다. LCEL 문법부터 랭체인 익히면서 많이 도움이 되었던 유투브입니다. 랭체인으로 LLM에게 다양한 기능을 부여해보고 싶은 분들은 꼭 보시길 바랍니다. 패스트캠퍼스에서도 강의를 제작하셨으니 구매하셔서 봐도 좋을 듯합니다.
코드 설명
랭그래프는 랭체인에서 만든 node, edge 다양한 개념을 도입해서 더욱 다양한 우리가 풀고자 하는 Task에 세밀한 워크플로우를 적용해서 결과를 가져올 수 있는 프레임워크입니다. 제가 해결하고자 하는 문제는 기존 루피 이력서 봇에 더욱더 다양한 Context와 양질의 정보를 주고 싶었습니다. 물론 RAG 아키텍처문제 일 수도 있지만, 파이프라인 자체가 구축되면 관련성체크를 하고 결과를 내보내면 더 좋은 서비스가 되지 않을까 생각을 했었습니다.

제가 구성한 예제는 다음과 같습니다. 사용자 정보를 retrieve 하고 , 크롤링된 직업정보를 하이퍼크로버 Context에 담기게끔 GPT-4o로 요약을 합니다. 그 후 LLM(루피봇)에게 질문을 던지는 로직이고, GPT-4o 가 job_info의 내용을 토대로 관련성 체크를 합니다. 그 후 웹검색을 진행하고, 여기서 job_info를 다시 한번 키워드를 뽑아서 웹검색을 통해서 정보를 보충해 주고 다시 루피봇에게 질문을 합니다. 그다음 related_info에서 관련성 여부를 체크합니다.(job_info, question, answer의 내용으로) True 인 경우는 end 처리하고, False인 경우는 다시 서치검색을 진행합니다. 계속 반복을 하게 됩니다.
이 과정이 완벽하단 느낌은 너무 없었습니다. 계속 구성하면서 바꾸고 바꾸고 했던 거 같습니다. 그래서 애초애 프로젝트 플로우를 잘 짜두고 하는 것이 이 LangGraph를 구현하는데 핵심이라고 느꼈습니다. 어떻게 노드를 연결할 것이고 , 조건부 에지를 어떻게 설정해서 순환이 되게끔 할 것인가가 큰 핵심입니다.
from typing import TypedDict
class GraphState(TypedDict):
question: str
context: str
job_info : str
answer: str
relevance: str
먼저 클래스 단위의 Graphstate를 선언해 주고 딕셔너리로, 키를 설정하고 그 키에 해당하는 값이 틀어오는 타입을 지정해 줍니다.
저는 질문, 정보, 직업정보, 답변, 관련성을 Graphstate로 선언을 해주었습니다.
from pdf import PDFRetrievalChain
pdf = PDFRetrievalChain(["user_data/김재현_CV경력서.pdf"]).create_chain()
pdf_retriever = pdf.retriever
pdf_chain = pdf.chain
PDF를 레트리버 하는 것이 제 Task 이기 때문에 Teddynote 님의 예제코드를 따라 사용하였습니다. Chunk는 500, overlap은 50 정도로 주어져있고, 내부 utils에서 Upstage Embedding을 사용하신걸 저는 HuggingFace 모델료 교체 사용하였고, 이번에는 hybrid Search와 같은 기술은 따로 사용하지 않았습니다. (나중에 노드자체로 구성해서) 애초에 재탐색하는 로직을 할 때 서치를 강화하는 느낌으로 짜 보려고 합니다.
from utils import format_docs, format_searched_docs
def retrieve_document(state: GraphState) -> GraphState:
retrieved_docs = pdf_retriever.invoke(state["question"])
retrieved_docs = format_docs(retrieved_docs)
return GraphState(context=retrieved_docs)utils의 선언된 함수들은 메타데이터를 통해 어디서 정보를 가져왔는지를 추출할 수 있는 함수입니다.
llm_answer 노드
def llm_answer(state: GraphState) -> GraphState:
question = state["question"]
context = state["context"]
job_info = state["job_info"]
response = pdf_chain.invoke({"question": question, "context": context,'job_info': job_info})
return GraphState(answer=response)블로그 글을 쓸 때마다 느끼는 거지만, 항상 정리하면서 보니깐 문제점이 많이 보입니다. llm_answer를 여러 개를 만들어서 해당 Query, Context를 알맞게 넣을 수 있겠구나 생각이 들었습니다. 위 llm_answers는 재호출 후 에도 사용되는 로직입니다. 유저가 쿼리를 던지면 -> RAG 파이프라인을 거쳐서 Context 와함께 답변을 하게 됩니다. 그 결과는 answer 값에 저장이 됩니다.
related_info 노드
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from clova_base import ClovaBaseLLM
from langchain_openai import ChatOpenAI
def related_info(state):
question = state["question"]
answer = state["answer"]
context = state["context"]
job_info = state["job_info"]
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"당신은 질문과 답변을 기반으로 관련하여 관련성이 있는지 없는지 체크하는 정보 봇입니다."
"답변은 True, False 로 출력하세요"
),
(
"human",
"#answer:{answer}의 내용을 토대로,job_info: {job_info}에 대한 관련성이 있는지 없는지 판단해주세요. 채용내용과 관련해서 답변이 적절하게 들어가있는지 판단하세요."
"True or False로 답변하세요 :",
),
]
)
model = ChatOpenAI(temperature=0, model="gpt-4o")
chain = prompt | model | StrOutputParser()
response = chain.invoke(
{"question": question, "answer": answer, "context": context,"job_info": job_info}
)
return GraphState(relevance=response)
def is_relevant(state: GraphState) -> GraphState:
return state["relevance"]해당 답변의 내용을 토대로 job_info 직업정보와 질문의 관련성 여부 즉 직업정보의 우대조건이라던지, 채용조건과 같은 그 내용을 내 이력서와 맵핑하기 위한 로직이라고 볼 수 있습니다. 판단을 해서 GPT는 답변을 True, False로 답변을 하게 됩니다. 그 관련성은 Relevence에 저장이 되고, 그 상태를 통해 조건부 에지에서의 False 라면 search로 향하고, 내용이 연관이 있다면 True로 구문이 끝나게 됩니다.
search_on_web 노드
from langchain_community.tools.tavily_search import TavilySearchResults
import re
def search_on_web(state: GraphState) -> GraphState:
search_tool = TavilySearchResults(max_results=5)
user_query = '''
# 지시사항
{combined_postings}을 보고 , 웹 검색을 하기 위한 키워드를 추출하고, 만들어주세요. 5개를 출력하세요
단, 회사와 관련된 채용정보와 관련된 키워드만 추출해주세요.
답변 :
'''.format(combined_postings=state["job_info"])
predict = search_model._call(user_query)
search_result = search_tool.invoke({"query": predict})
search_result = format_searched_docs(search_result)
return GraphState(
context=search_result
)
def is_relevant(state: GraphState) -> GraphState:
return state["relevance"]
이전에 한번 구성해 봐서 apikey 가 있었는데 아래의 홈페이지 가입하시고, API 환경설 저어 해주셔야 웹검색 로직을 수행할 수 있습니다.
Tavily AI
app.tavily.com
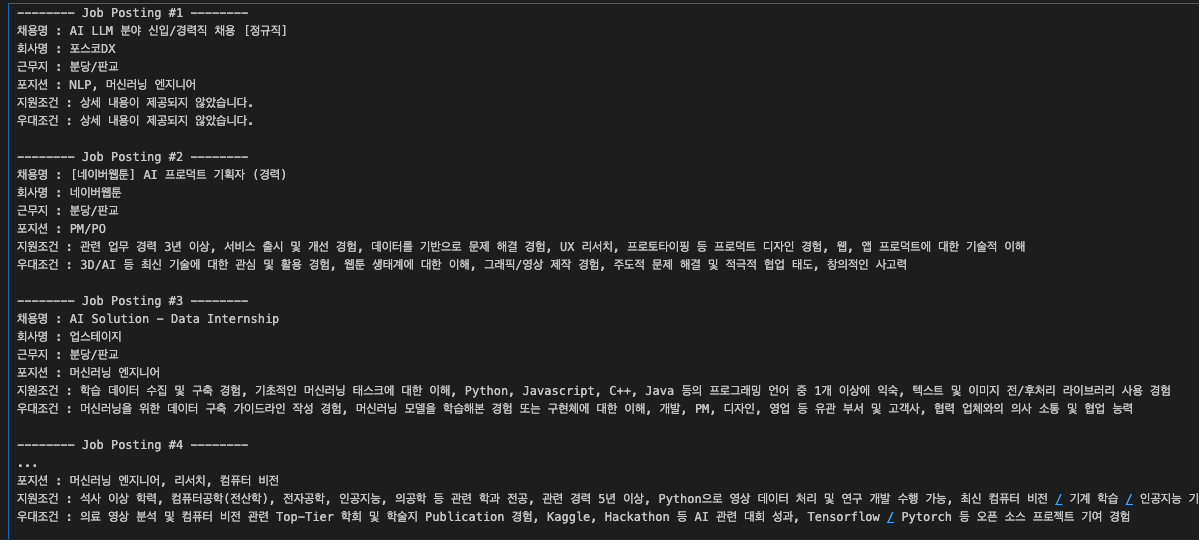
코드는 job_info는 이렇게 GPT를 통해 요약 후 문자열로 합쳐놓았고 여기서 다시 키워드를 추출해서, 웹검색을 하는 방식으로
text = "1. 포스코DX AI LLM 분야 신입/경력직 채용\n2. 네이버웹툰 AI 프로덕트 기획자 경력 채용\n3. 업스테이지 AI Solution - Data Internship 채용\n4. 한국딥러닝 AI 엔지니어 데이터 1년 이상 채용\n5. 오스템임플란트 AI 인공지능 자동화 기술 연구 및 개발 채용"
이 쿼리 자체가 검색으로 들어가서 5개의 결괏값을 반환하여 Context에 추가됩니다. 이 과정에서 별의별 정보가 다 들어올 수 있기 때문에 핸들링이 필요할 수 있습니다. 저는 이 과정에서 변호사 관련 Context가 들어와서 결괏값이 변호사로 리턴이 되는 경험을 했었습니다.
workflow 구성
from langgraph.graph import END, StateGraph
from langgraph.checkpoint.memory import MemorySaver
workflow = StateGraph(GraphState)
workflow.add_node("retrieve", retrieve_document)
workflow.add_node("retrieve_job_info", retrieve_job_info)
workflow.add_node("llm_answer", llm_answer)
workflow.add_node("related_info", related_info)
workflow.add_node("search_on_web", search_on_web)
workflow.add_edge("retrieve", "retrieve_job_info")
workflow.add_edge("retrieve_job_info", "llm_answer")
workflow.add_edge("llm_answer", "related_info")
workflow.add_edge("related_info","search_on_web")
workflow.add_edge("search_on_web","llm_answer")
workflow.add_conditional_edges(
"related_info",
is_relevant,
{
"True": END,
"False": "search_on_web",
},
)
workflow.set_entry_point("retrieve")
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)먼저 노드를 선언을 해주고 에지는 노드 간 방향을 뜻해서 방향을 잡아주면 됩니다. 컨디셔널에지에서 위에서 말한 대로 트루일 때 END, False 일때 검색을 하게끔 해주고 시작은 Retrieve에서 시작이 되고, LangChain은 이 일련의 과정을 메모리를 통해 관리를 하기 때문에 Memory를 선언해서 이 내용들이 적재적소에 저장이 되어 , 컨디셔널 에지, 윗 단계로 다시 올라가고 하나의 CI/CD 와 같은 워크플로우가 구축이 가능하게 해 줍니다.
LangGraph 실행
import pprint
from langgraph.errors import GraphRecursionError
from langchain_core.runnables import RunnableConfig
config = RunnableConfig(
recursion_limit=12, configurable={"thread_id": "CORRECTIVE-SEARCH-RAG"}
)
inputs = GraphState(
question="김재현의 이력과 채용공고에서의 채용가능성 있는 회사는 어떤게 있을까요?"
)
try:
for output in app.stream(inputs, config=config):
for key, value in output.items():
pprint.pprint(f"Output from node '{key}':")
pprint.pprint("---")
pprint.pprint(value, indent=2, width=80, depth=None)
pprint.pprint("\n---\n")
except GraphRecursionError as e:
pprint.pprint(f"Recursion limit reached: {e}")
최대 호출 한도를 12를 설정을 해줍니다. (돈 과금 많이 될 수 있음 주의) , inputs state에 question 즉 유저쿼리를 넣어주는 것입니다. 그러고 그 dict 형태의 State들은 노드들을 거치면서 정보를 입력하고, 수정하는 일련의 과정이라 할 수 있습니다.
결과는 일단 처음시도 때엔 websearch가 정보가 쌓이면서 이상한 정보가 쌓여서 할루시네이션이 유발되는 모습이 보였습니다. 그래서 요약등 로직을 넣은 것이고, 하이퍼크로버의 max_tokens가 4096의 한계로 인하여 Context의 다양한 정보를 주는 과정에서 Error 가 발생하는 모습이 보였습니다. 짧은 단어로 로직을 테스트 했을땐 매우 만족스러운 답변을 볼 수가 있었습니다. 이 부분은 하이퍼클로바의 물리적인 한계이기 때문에 빠르게 업데이트가 되었으면 하는 바람입니다. RoPE 기반 포지셔널 임베딩을 사용하는 걸로 Long Context 가 지원되는 걸로 아는데 빠르게 업데이트되었으면 합니다.
물론 일정 검색하고, 요약하고, 추론하는 과정에서 시간이 조금 걸립니다. 실시간응답 기반보다는 일정 레이턴시가 느려도 상관없는 Task에 정확성을 요하는 작업에 수행하는 것이 효과적일 듯합니다. 다른 시도를 해보고 있는 것은 Gemini, Claude, Clova, GPT로 RAG 답변을 비동기 처리해서 앙상블 하는 로직을 랭그래프로 구현해 보면 재밌을 거 같아서 기획 중입니다.
'NLP' 카테고리의 다른 글
| Gemini와 LangChain을 활용한 멀티모달 삼진 하이라이트 시스템 (0) | 2024.07.30 |
|---|---|
| 나혼자 만드는 금융권 LLM Assistant - (1) 페르소나 모델 만들기 (1) | 2024.07.19 |
| HyperClova X 를 통한 RAG 기반 이력서 비서 (0) | 2024.07.01 |
| RAG 시스템 을 구축하기 위한 데이터 전처리 - PDF (0) | 2024.06.25 |
| HyperClova X 를 Sliding Window 활용하기 - 루피챗 기억 넣기 (0) | 2024.06.21 |



