HyperClovaX에 2024 미쉐린 음식점을 학습시키자!
나만의 원피스 루피 챗봇 만들기 with HyperClovaXHyper CLOVA 스터디를 참여하게 되었다🙇이직준비와 이직 신입 적응기를 거치며 5월은 빠르게 흘러갔다. 매번 일을 벌이는 걸 좋아하는 나에게 찾아온
hyun941213.tistory.com

HyperClova Study를 하면서 여러 데이터를 생성하는 방법과 Fine-tunning을 하는 방법을 다루었었는데요. 이제 RAG를 통해서 조금 더 하이퍼 크로버에게 정보를 제공하면서 더 좋은 답변을 만들기 위한 개발을 해보겠습니다.
크로버스튜디오에는 스킬트레이너라고 해서 OpenAI에서 GPT에게 지원하는 비슷한 기능이라 볼 수 있는 Function Calling과 같은 API 형태의 기능이 존재하고 있으나 아쉽게도 HCX-003 에만 적용이 되고 제가 튜닝한 모델에 유연하게 쓰지는 못하고 있습니다. 어떻게 보면 Cue: 의 기능이 이것으로 구현되지 않았나 생각합니다. 이 스킬 트레이너의 장점은 HCX 가 Query를 분석해서 API 기능을 호출할 수 있도록 한다는데 써보진 않아서 잘은 모르겠습니다. 결국은 RAG를 붙여야 한다 결론..

(3부) CLOVA Studio를 이용해 RAG 구현하기
이 cookbook은 네이버 클라우드 플랫폼에서 CLOVA Studio의 기능을 활용하여 RAG(Retrieval Augmented Generation)를 구현하는 방법을 설명합니다. RAG에 사용된 데이터는 HTML 형식이며, CLOVA Studio의 문단 나누기 A
www.ncloud-forums.com
위의 포럼글을 따라하며 RAG를, 크로버스튜디오의 기능을 통해서 구현을 해도 상관은 없으나, Langchain을 아무래도 오랫동안 써왔고 또 Reference 가 생각보다 많이 없길래 이왕 하는 김에 나는 랭체인에 대한 이해도는 있으니 그냥 붙이고 포럼에 등록하면 되겠다 생각을 했습니다. 그러나 문제는 HCX가 아직 Langchain에서 정식으로 지원을 하지 않고 있습니다.
그러다 든 생각은 HuggingFace 모델이나 다른 API 형태의 언어모델을 ChatOpenAI 형태로 호출을 해서 GPT 호출 방식으로 쓰는것은 알고 있었는데 그게 적용이 될 것 같다고 풀잎스쿨에서 현석님이 그러셨고, 조금 더 찾아보다가 Langchain에 CustomLLM이라고 사용자 LLM을 model로 쓸 수 있게 가이드에 문서가 있었습니다.
Custom LLM | 🦜️🔗 LangChain
This notebook goes over how to create a custom LLM wrapper, in case you want to use your own LLM or a different wrapper than one that is supported in LangChain.
python.langchain.com
from typing import Any, Dict, Iterator, List, Mapping, Optional
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.outputs import GenerationChunk
class CustomLLM(LLM):
""" 입력의 첫 `n`자를 에코하는 사용자 지정 채팅 모델입니다.
LangChain에 구현을 기여할 때는 초기화 파라미터를 포함한
초기화 매개변수를 포함한 모델, 초기화 방법 예시
모델을 초기화하는 방법의 예시와 관련성이 있는
기본 모델 문서 또는 API에 대한 링크를 포함하세요.
예시:
.. 코드 블록:: 파이썬
model = CustomChatModel(n=2)
result = model.invoke([HumanMessage(content="hello")])
result = model.batch([[휴먼메시지(내용="hello")]),
[HumanMessage(content="world")]]))
"""
Translated with DeepL.com (free version)
n: int
"""The number of characters from the last message of the prompt to be echoed."""
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
""" 주어진 입력에 대해 LLM을 실행합니다.
LLM 로직을 구현하려면 이 메서드를 재정의합니다.
Args:
prompt: 생성할 프롬프트입니다.
stop: 생성할 때 사용할 중지 단어. 모델 출력은 중지 하위 문자열이
에서 모델 출력이 끊어집니다.
중지 토큰이 지원되지 않는 경우 NotImplementedError를 발생시키는 것을 고려하세요.
run_manager: 실행을 위한 콜백 관리자.
**kwargs: 임의의 추가 키워드 인자. 일반적으로 모델 공급자 API 호출에
로 전달됩니다.
returns:
문자열로 출력되는 모델입니다. 실제 완성된 모델에는 프롬프트가 포함되지 않아야 합니다.
"""
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[: self.n]
def _stream(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[GenerationChunk]:
""" 주어진 프롬프트에서 LLM을 스트리밍합니다.
이 메서드는 스트리밍을 지원하는 서브클래스에 의해 재정의되어야 합니다.
구현되지 않은 경우, 스트리밍 호출의 기본 동작은 다음과 같습니다.
모델의 비스트리밍 버전으로 폴백하고 출력을 단일 청크로
출력을 단일 청크로 반환하는 것입니다.
Args:
prompt: 생성할 프롬프트입니다.
stop: 생성할 때 사용할 중지 단어. 모델 출력은 이러한 하위 문자열이
하위 문자열의 첫 번째 발생 시 모델 출력이 차단됩니다.
run_manager: 실행을 위한 콜백 관리자.
**kwargs: 임의의 추가 키워드 인자. 일반적으로 모델 공급자 API 호출에
로 전달됩니다.
반환값:
GenerationChunks의 이터레이터.
"""
for char in prompt[: self.n]:
chunk = GenerationChunk(text=char)
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk)
yield chunk
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Return a dictionary of identifying parameters."""
return {
#모델 이름을 통해 사용자는 사용자 지정 토큰 카운팅을 지정할 수 있습니다.
# 규칙을 지정할 수 있습니다
#(예: LangSmith 사용자의 경우는 모델에
대한 토큰 당 가격을 제공하고 주어진 LLM에 대한 모니터링모니터링할 수 있습니다.)
"model_name": "CustomChatModel",
}
@property
def _llm_type(self) -> str:
"""Get the type of language model used by this chat model. Used for logging purposes only."""
return "custom"
공식문서의 코드입니다. 구성은 클래스의 형태에서 @ property 데코레이터는 클래스 내의 메서드를 속성처럼 사용할 수 있게 합니다. 이를 통해 메서드를 호출할 필요 없이 속성처럼 접근할 수 있습니다.(코드간결성) 그리고 최근에 알게 된 사실이라 부끄럽지만 Langchain 에서 '|'를 사용해서 체이닝을 할 때 오퍼레이터로 여러 함수기능을 파이프라인 있게 만들 때 사용한다고 합니다. 그냥 쓰는 것보단 알고 쓰는 게 더 좋은 것 같습니다.
n 은 글자를 반환하는 수라서 보시면 self.n return 하는 모습을 볼 수 있습니다. n 으로 핸들링이 가능한 파라미터지만 굳이? 쓸 필요능 없어 보입니다. 저는 이전에 하이퍼크로버를 inference 하기 위해 짜둔 코드를 응용을 하였습니다.
다음은 Docs 간략한 메서드 설명입니다.
사용자가 구현해야할 2가지
| 메서드 | 설명 |
| _call | 문자열과 몇 가지 선택적 중지 단어를 받아 문자열을 반환합니다. invoke에 사용됩니다. |
| _llm_type | 로깅 목적으로만 사용되는 문자열을 반환하는 속성입니다. |
필요에 따라 구현가능한 옵션
| 메서드 | 설명 |
| _indentifying_params | 모델을 식별하고 LLM을 인쇄하는 데 사용되며 사전을 반환해야 합니다. @property를 활용 |
| _acall | ainvoke에서 사용하는 _call의 비동기 네이티브 구현을 제공합니다. |
| _stream | 토큰별로 출력 토큰을 스트리밍하는 메서드입니다. |
| _astream | 스트림의 비동기 네이티브 구현을 제공합니다. 최신 LangChain 버전에서는 기본값이 _stream으로 설정됩니다. |
import json
import requests
class CompletionExecutor:
def __init__(self, host, api_key, api_key_primary_val, request_id):
self._host = host
self._api_key = api_key
self._api_key_primary_val = api_key_primary_val
self._request_id = request_id
def execute(self, completion_request):
headers = {
"X-NCP-CLOVASTUDIO-API-KEY": self._api_key,
"X-NCP-APIGW-API-KEY": self._api_key_primary_val,
"X-NCP-CLOVASTUDIO-REQUEST-ID": self._request_id,
"Content-Type": "application/json; charset=utf-8",
"Accept": "text/event-stream"
}
response = requests.post(
self._host + "/testapp/v1/chat-completions/HCX-003", # 본인 튜닝 API 경로 사용도 가능 test App 에서
headers=headers,
json=completion_request,
stream=True
)
# 스트림에서 마지막 'data:' 라인을 찾기 위한 로직
last_data_content = ""
for line in response.iter_lines():
if line:
decoded_line = line.decode("utf-8")
if '"data":"[DONE]"' in decoded_line:
break
if decoded_line.startswith("data:"):
last_data_content = json.loads(decoded_line[5:])["message"]["content"]
return last_data_content
def get_response_data(user_query):
sys_prompt ='''
당신은 해적왕 루피입니다. 패기있고 당당하게 답을하세요. 정보가 주어지면 정보를 기반으로 답변을 작성해주세요.
'''
preset_text = [{"role":"system","content":sys_prompt}, #지시사항
{"role":"user","content":user_query},]
request_data = {
"messages": preset_text,
"topP": 0.6,
"topK": 0,
"maxTokens": 1024,
"temperature": 0.5,
"repeatPenalty": 1.2,
"stopBefore": [],
"includeAiFilters": False
}
executor = CompletionExecutor(
host='https://clovastudio.stream.ntruss.com/',
api_key='your api key',
api_key_primary_val='your api key',
request_id='request id'
)
response_data = executor.execute(request_data)
return response_data
이 코드자체도 클래스로 묶여있기 때문에 따로 상속을해서 선언을 해도 될듯하다 생각을 했는데, 그냥 가이드 문서대로 리턴값들만 맵핑해 주면 되겠구나 생각을 했습니다.
from typing import Any, List, Mapping, Optional
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
import json
import requests
#Custom LLM LlmClovaStudio
class LlmClovaStudio(LLM):
"""
Custom LLM class for using the ClovaStudio API.
"""
host: str
api_key: str
api_key_primary_val: str
request_id: str
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.host = kwargs.get('host')
self.api_key = kwargs.get('api_key')
self.api_key_primary_val = kwargs.get('api_key_primary_val')
self.request_id = kwargs.get('request_id')
@property
def _llm_type(self) -> str:
return "custom"
def _call(self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None
) -> str:
"""
Make an API call to the ClovaStudio endpoint using the specified
prompt and return the response.
"""
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
headers = {
"X-NCP-CLOVASTUDIO-API-KEY": self.api_key,
"X-NCP-APIGW-API-KEY": self.api_key_primary_val,
"X-NCP-CLOVASTUDIO-REQUEST-ID": self.request_id,
"Content-Type": "application/json; charset=utf-8",
"Accept": "text/event-stream"
}
sys_prompt = '''
한국어로 답변하세요 당신은 루피입니다.
'''
preset_text = [{"role": "system", "content": sys_prompt}, {"role": "user", "content": prompt}]
request_data = {
"messages": preset_text,
"topP": 0.6,
"topK": 0,
"maxTokens": 1024,
"temperature": 0.5,
"repeatPenalty": 1.2,
"stopBefore": [],
"includeAiFilters": False
}
response = requests.post(
self.host + "your api address", # 본인이 finetunning 한 API 경로 , 일반 HCX03써도 무관합니다
headers=headers,
json=request_data,
stream=True
)
# 스트림에서 마지막 'data:' 라인을 찾기 위한 로직
last_data_content = ""
for line in response.iter_lines():
if line:
decoded_line = line.decode("utf-8")
if '"data":"[DONE]"' in decoded_line:
break
if decoded_line.startswith("data:"):
last_data_content = json.loads(decoded_line[5:])["message"]["content"]
return last_data_content
# 선언할때 테스트앱 생성해서 key 값을 받아오세요
llm = LlmClovaStudio(
host='https://clovastudio.stream.ntruss.com/',
api_key='your key',
api_key_primary_val='your key',
request_id='request id'
)
# LCEL invoke
response = llm.invoke("미쉐린 식당 추천해줘!")
print(response)
위처럼 설정을 해주면 됩니다. 어차피 프로덕트 레벨의 무언가를 만들게 아니라서 파라미터는 그냥 고정값으로 설정을 해두었고, 이건 그때 그때 바꿔서 쓰시면 될 듯합니다! ChatTemplate 가 어떻게 적용되는지는 저도 잘 모르겠는데 llm.invoke 하면서 prompt 변수 유저쿼리로 들어가서 request해주는 듯합니다. 위처럼 구성해 주시면 Langchain + HyperClovaX 결합 성공입니다.
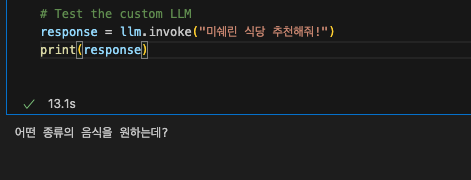
제가 원하는 대로 텍스트 값만 출력을 시키는데요 Sliding window 를 통해 이전 history를 기억하게 끔 해서 원활한 대화 세션이 구성되게 끔 구현도 해야 할 듯합니다.
이제 우리는 Langchain 이 지원하는 수많은 기능을 쓸 수 있습니다. 오늘 흥미로운 Langchain Agent 글을 보았는데 여러 LLM을 체이닝 시켜서 여러 모델을 결합시키는 에이전트 글을 보았는데, ChatGPT-3.5로 파인튜닝 시켜서 두 개를 통해 의사결정하는 Agent를 만들어도 되고 쓰임새가 다양해 보이네요.
LangChain Agent - Vocode
Overview LangChain offers tooling to create custom LLM pipelines for complex decision-making. Through LangChain, you can manage your LLM and prompts, and combine them with advanced techniques like RAG and multi-stage prompting, and sub-chains. The library
docs.vocode.dev
이번 포스팅은 여기까지 마무리하겠습니다. RAG 붙여서 다음 프로젝트를 완성시키겠습니다. Github 에 코드는 계속 업로드 중입니다.
GitHub - jh941213/HyperClovaX_Study: 하이퍼클로바스터디
하이퍼클로바스터디. Contribute to jh941213/HyperClovaX_Study development by creating an account on GitHub.
github.com
'NLP' 카테고리의 다른 글
| RAG 시스템 을 구축하기 위한 데이터 전처리 - PDF (0) | 2024.06.25 |
|---|---|
| HyperClova X 를 Sliding Window 활용하기 - 루피챗 기억 넣기 (0) | 2024.06.21 |
| HyperClovaX에 2024 미쉐린 음식점을 학습시키자! (1) | 2024.06.19 |
| 나만의 원피스 루피 챗봇 만들기 with HyperClovaX (33) | 2024.06.14 |
| Chat Vector 를 통한 한국어 모델 튜닝 (0) | 2024.06.12 |



