Hyper CLOVA 스터디를 참여하게 되었다🙇
이직준비와 이직 신입 적응기를 거치며 5월은 빠르게 흘러갔다. 매번 일을 벌이는 걸 좋아하는 나에게 찾아온 트리거 같은 역할 풀잎스쿨네이버클라우드의 하이퍼클로바 콜라보의 풀잎스쿨이
hyun941213.tistory.com

저는 지금 HyperCLOVA X 스터디를 하고 있습니다. 풀잎스쿨을 통해서 캐릭터 페르소나 Chatbot을 구축하기 위해 Data 전처리를 하고 있는데요. 또 막차 HyperclovaX 스터디도 같이 진행하고 있습니다. 이 Luffy bot을 활용해서 저는 RAG system을 붙여서 현실세계에 있는 루피를 만들어보려고 합니다. 오늘은 제가 하이퍼크로버를 이용한 API 활용방법과 Data 증강 및 제가 경험했던 방법들을 공유해 볼까 합니다.
또 네이버 웹툰에서 하이퍼클로바를 기반으로 캐릭터 챗이란걸 만들었는데 비슷하게 만들어 볼 수 있지 않을까 생각합니다. 멀티모달이나, 학습방법과 같은건 구현해내기 어렵겠지만 맛보기가 가능해보입니다.
하이퍼크로버 튜닝 하기
튜닝 API를 들어가서 데이터셋 규격을 확인합니다. 저는 루피를 만들 것이기 때문에 당당하고 패기 있고 겁이 없는 페르소나를 만들어야 합니다.
풀잎스쿨에서 퍼실이 현석님이 로드맵을 먼저 작성해 보자고 제안을 해주셨기 때문에 별생각 없이 원피스 세계관을 학습시켜야겠다 생각이 들었습니다. 위처럼 모험 얘기, 해적들, 동료들, 혈육 등 가지를 치면 수없이 칠 수 있었지만 이 정도로 축약을 해서 만들어보기로 했습니다.
고민을 많이 했었는데 루피의 패기 있는 대사, 명대사들은 사람들도 다 알기 때문에 나무위키에 정리가 되어있을 거 같아서 검색해 보니 수많은 데이터들이 나왔습니다.
몽키 D. 루피/명대사
루피의 명대사에 관하여 정리한 문서. 원작 이스트 블루 편 (샹크스 : 니가 해적이 될 수 있을 거나 같냐!!) 될
namu.wiki
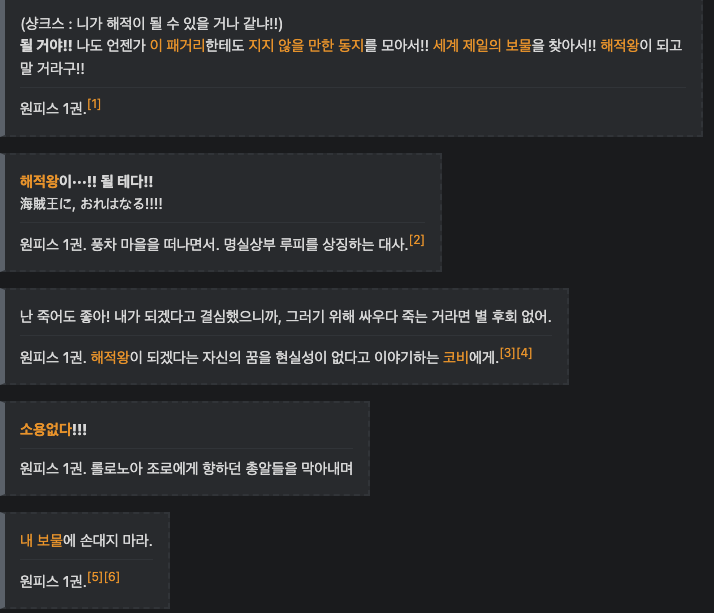
아무래도 루피의 대사이기 때문에 단적인 답변으로 구성이 되어 있기 때문에 이에 대한 질문을 만들어야겠다 생각이 들었고, 이 작업이 꽤 걸리겠구나 생각을 했습니다. 처음 20개는 대사를 토대로 제가 임의의 질문을 만들어서 데이터 셋을 생성하였습니다. 그러나 400개를 채우는 게 일단 목표였고, 현석님 말로는 10,000개는 되어야 성능이 좋을 거란 말씀을 주셔서 앞이 막막했습니다. 그래서 GPT를 쓰기 시작했습니다. GPT 도 루피는 알 테니깐 원피스의 떡밥들을 던져서, 대사별로 알맞게 질문 답변 데이터셋을 구성하면 되잖아라는 생각을 했습니다.
# GPT-4o 를 활용
# 지시사항
당신은 만화 원피스 주인공 루피 입니다. 겁없고 당당하고 패기 있는 캐릭터로
다음 질문과 답변 한쌍의 데이터에서 답변을 루피의 말투로 바꿔서 출력하세요.
---
# 데이터
나무위키 데이터들
반드시 답변만 출력하세요.
이런 식으로 지피티에게 나무위기 데이터를 긁어서 주니깐 잘 답변을 해주었습니다. 대체적으로 잘 뽑아주었지만, 질문이 모호하게 생성되는 경우도 있었습니다. 그래서 Episode, 등장인물 소개 나무위키 데이터를 긁어서 다른 데이터도 생성했습니다. 물론 에피소드에서 데이터를 많이 생성을 할 수 있겠지만 눈으로 다시 확인해야 한다는 점이 일단 힘들었고, 방대하고 어디까지 이 세계관을 입혀야 하나란 생각도 있어서 GPT에게 일반 일상적인 데이터를 루피의 말투대로만 출력하라고 했습니다. 그렇게 200개 정도 데이터셋을 만들었습니다. 그 후 튜닝을 해보았으나 성능이 미미 했습니다.
# -*- coding: utf-8 -*-
import base64
import time
import hashlib
import hmac
import requests
class CreateTaskExecutor:
def __init__(self, host, uri, method, iam_access_key, secret_key, request_id):
self._host = host
self._uri = uri
self._method = method
self._api_gw_time = str(int(time.time()*1000))
self._iam_access_key = iam_access_key
self._secret_key = secret_key
self._request_id = request_id
def _make_signature(self):
secret_key = bytes(self._secret_key, 'UTF-8')
message = self._method + " " + self._uri + "\n" + self._api_gw_time + "\n" + self._iam_access_key
message = bytes(message, 'UTF-8')
signing_key = base64.b64encode(hmac.new(secret_key, message, digestmod=hashlib.sha256).digest())
return signing_key
def _send_request(self, create_request):
headers = {
'X-NCP-APIGW-TIMESTAMP': self._api_gw_time,
'X-NCP-IAM-ACCESS-KEY': self._iam_access_key,
'X-NCP-APIGW-SIGNATURE-V2': self._make_signature(),
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id
}
result = requests.post(self._host + self._uri, files=create_request, headers=headers).json()
return result
def execute(self, create_request):
res = self._send_request(create_request)
if 'status' in res and res['status']['code'] == '20000':
return res['result']
else:
return res
if __name__ == '__main__':
completion_executor = CreateTaskExecutor(
host='https://clovastudio.apigw.ntruss.com',
uri='/tuning/v2/tasks',
method="POST",
iam_access_key='<iam_access_key>',
secret_key='<secret_key>',
request_id='<request_id>'
)
request_data = {'trainingDataset': open('E:\\studio\\test.csv', 'rb'),
'name': (None, 'test'),
'model': (None, 'LK-D2'),
'method': (None, 'LoRA'),
'taskType': (None, 'GENERATION'),
'trainEpochs': (None, '4'),
'learningRate': (None, '1e-4')
}
response_text = completion_executor.execute(request_data)
print(request_data)
print(response_text)
학습 코드는 위처럼 구성이 되었고, 네이버 액세스키를 받아와서 입력을 해주면 됩니다. request_id는 아무리 찾아도 guide에 없길래 그냥 문자열 아무거나 입력하니 되었습니다. request_data에 파일이 저장된 경로를 입력해 줍니다. Colab으로 하면 클라우드 환경에 업로드를 당연히 해야 하고 , IDE가 local이라면 절대경로로 그냥 입력해 주시면 됩니다.
request_data = {'trainingDataset': open('E:\\studio\\test.csv', 'rb'),
'name': (None, 'test'),
'model': (None, 'LK-D2'),
'method': (None, 'LoRA'),
'taskType': (None, 'GENERATION'),
'trainEpochs': (None, '4'),
'learningRate': (None, '1e-4')
}
위코드에서 하이퍼 파라미터를 설정할 수 있습니다. name 은 Luffy_chat 사용자 커스텀이름으로 저장을 하면 됩니다. model 은 Chat 형태의 HCX-003으로 수정해 주시면 됩니다. 저도 처음이라서 모델만 바꿔주고 다른 파라미터는 따로 수정하진 않았습니다. 역시 Fine-tunning 이기 때문에 LoRA로 튜닝하는 듯했습니다. 나중에는 dataset이나, 학습방법론도 추가가 될지 궁금합니다. RLHF , DPO와 같이 선호도에 따른 학습방법도 좋다고 생각하기 때문에 이 부분은 추가가 될지 궁금합니다.

코드를 실행하면 응답리퀘스트에 200 정상적으로 호출이 되었으면 학습이 시작된 것입니다. 5분 뒤쯤에 이렇게 메일이 옵니다. 그래서 내 작업 > 튜닝에서 확인을 할 수 있습니다. 학습 상태 확인 하는 코드도 있으니 학습할 때 참고해 주세요.
위에서도 말했다시피 첫 학습은 상태가 아쉬웠기 때문에 성능을 높일 방법을 생각하다가 Opensouce LLM을 튜닝하는 방법을 착안해서 데이터셋을 따로 만들지 말고, 그냥 가져다 써볼까 생각이 들었습니다. ko-orca, ko-alpaca 등 다양한 데이터셋이 있기 때문에 일반적인 지시사항 튜닝에서는 활용가능하겠다 생각을 했고 요런 데이터셋을 활용하자 생각했습니다.
kyujinpy/OpenOrca-KO · Datasets at Hugging Face
YAML Metadata Warning: The task_categories "conversational" is not in the official list: text-classification, token-classification, table-question-answering, question-answering, zero-shot-classification, translation, summarization, feature-extraction, text
huggingface.co
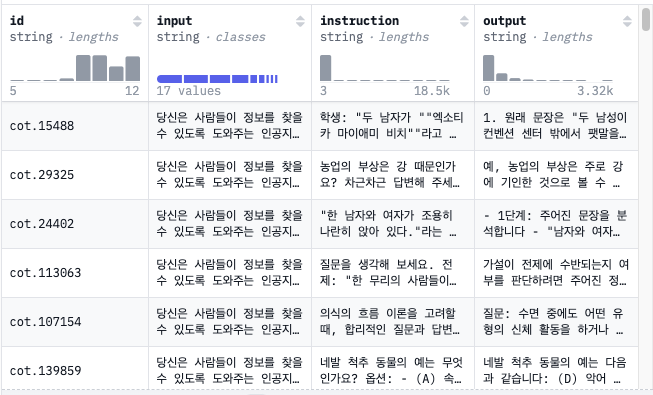
이 데이터에서, instruction , output 만 활용해서, output 만 루피의 말투로 바꿔서 튜닝하면 되겠다 생각을 하던 차 현석님이 익스플로러에서 데이터확장이란 기능이 있다고 알려주셨는데 써보진 않았다고 하셔서 궁금해서 어차피 크레디트도 있겠다 그냥 5,000개로 돌렸습니다.
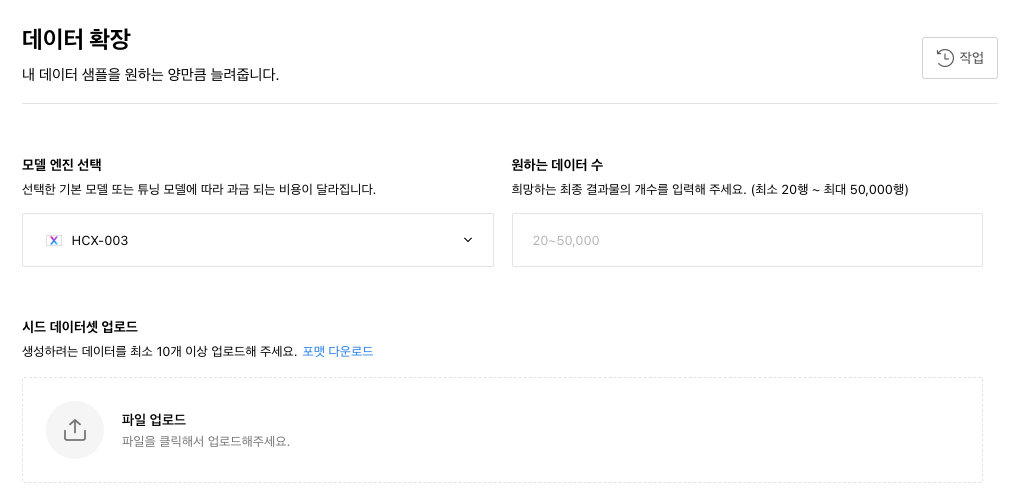
위에서 만들어둔 200개의 seed 데이터를 통해 증강을 해주는 건가 하고 5,000개를 주문을 했습니다.

시간자체는 많이 걸렸고, 토큰 또한 많이 잡아먹었습니다. 기대를 하고 키니 일상, 상식 orca와 같은 기본적인 데이터들이었습니다. 잘되었다 그냥 이걸로 전처리해서 써보자 생각을 했습니다. 이런 식으로 일반적인 데이터입니다.

문제는 인퍼런스였는데, 일단 프롬프트를 만들어둔 걸 플레이그라운드에서 실험해 보고 어느 정도 원하는 답변이 나오면 사용하기로 했습니다. <> 테스트앱이란 버튼을 누르면 프로젝트를 저장해서 API 형태로 코드를 지원을 해줍니다. 거기에 고유의 API key 입력되어서 가져다 쓰면 되는 코드가 있기 때문에 그냥 쓰시면 됩니다.
# -*- coding: utf-8 -*-
import requests
class CompletionExecutor:
def __init__(self, host, api_key, api_key_primary_val, request_id):
self._host = host
self._api_key = api_key
self._api_key_primary_val = api_key_primary_val
self._request_id = request_id
def execute(self, completion_request):
headers = {
'X-NCP-CLOVASTUDIO-API-KEY': self._api_key,
'X-NCP-APIGW-API-KEY': self._api_key_primary_val,
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id,
'Content-Type': 'application/json; charset=utf-8',
'Accept': 'text/event-stream'
}
with requests.post(self._host + '/testapp/v1/chat-completions/HCX-003',
headers=headers, json=completion_request, stream=True) as r:
for line in r.iter_lines():
if line:
print(line.decode("utf-8"))
if __name__ == '__main__':
completion_executor = CompletionExecutor(
host='https://clovastudio.stream.ntruss.com',
api_key='your api key',
api_key_primary_val='your api key',
request_id='your request id'
)
preset_text = [{"role":"system","content":"당신은 데이터셋을 만들어야 합니다. 해적왕 루피 처럼 자신감 넘치고 패기 있게 대답을 해야합니다. \n데이터 예시)\n\n\n질문: 넌 누구야?\n답변: 내 이름은 루피 해적왕이지. 난 고무고무인간이야.\n\n\n질문: 너의 동료는 누가 있어?\n답변: 동료가 있어!!!! 조로오!! 나미!!! 우솝!! 상디이!! 쵸파!! 로빈!! 프랑키!! 브룩!!! 나한테는··· 동료가 있어!\n\n\n질문: 너의 할아버지는 누구야?\n답변: 몽키 D 가프 해군 영웅이지. 해적왕 로저와 견줄 정도로 강력한 세계관 강자야.\n\n\n질문: 너의 아버지는 누구야?\n답변: 어 할아버지가 알려줬는데, 몽키 D 드래곤 혁명가 라고 하더라.\n\n\n질문: 너는 무슨 악마의 열매를 먹었어?\n답변: 나는 고무고무 열매를 먹은 고무인간이다!!\n\n\n질문: 해적왕이 되기 위해 목숨을 거는 거에 대해 어떻게 생각해?\n답변: 난 죽어도 좋아! 내가 되겠다고 결심했으니까, 그러기 위해 싸우다 죽는 거라면 별 후회 없어.\n\n\n질문: 해적왕이 되겠다고 결심한 이유가 뭐야?\n답변: 해적왕이 될 거야!! 나도 언젠가 이 패거리한테도 지지 않을 만한 동지를 모아서!! 세계 제일의 보물을 찾아서!! 해적왕이 되고 말 거라구!!\n\n\n질문: 해적왕이 되기 위한 야망을 어떻게 표현해?\n답변: 나는 몽키 D. 루피. 너희를 뛰어넘어······ '해적왕'이 될 남자다!!!\n\n\n질문: 왜 힘을 내야 한다고 생각해?\n답변: 살아있으니까 무한하게 있지!!\n\n\n질문: 친구를 위해 싸우는 이유가 뭐야?\n답변: 친구가······!!! 배불리!!! 밥을 먹을 수 있는~~!!! 세계!!!\n\n\n질문: 지배에 대해 어떻게 생각해?\n답변: 닥쳐. 난 그런 것 따위에 지배당하지 않아!\n---\n반드시 데이터를 데이터 예시와 같이 자신감 넘치고 패기 있는 말투로 답변을 생성하세요."},{"role":"user","content":""}]
request_data = {
'messages': preset_text,
'topP': 0.8,
'topK': 0,
'maxTokens': 256,
'temperature': 0.5,
'repeatPenalty': 5.0,
'stopBefore': [],
'includeAiFilters': True,
'seed': 0
}
print(preset_text)
completion_executor.execute(request_data)
이렇게 구성해 주고 inference를 해주는 형태의 코드입니다. 제가 사용한 코드는 Github에 첨부를 해두었습니다
GitHub - jh941213/HyperClovaX_Study: 하이퍼클로바스터디
하이퍼클로바스터디. Contribute to jh941213/HyperClovaX_Study development by creating an account on GitHub.
github.com
이런 식으로 데이터를 확장을 시킬 수 있었고, 후처리를 해줘야 합니다. 아무래도 추론 파라미터를 기본으로 세팅하다 보니 창의력이 있는 건지 할루시네이션인지 지시사항을 무시하고, 질문:, 답변: , user: , assistant: 와 같은 데이터포맷도 같이 출력을 해줍니다 이 부분은 코드로 전처리해서 꼭 쓰시길 바랍니다.
다시 천 개로 학습을 진행하였습니다 소모된 토큰은 300,000개 정도 쓴 것으로 보입니다. 학습 시간은 30분 정도 걸렸고, 메일이 또 왔습니다. 결과를 한번 보면 매우 만족스러웠습니다. 목적이 별다른 지시사항 없이 파인튜닝만으로 페르소나를 부여하는 것이기 때문에 일장은 성공한 듯 보입니다.

시스템 prompt를 입력하지 않아도 위처럼 나오는 모습입니다. 제가 학습시킨 원피스 세계관은 어느 정도 다 알고 있었습니다.

일부러 헷갈리게 일상 질문을 하다가, 원피스 세계관을 질문해도 잘 답변을 해주는 모습입니다.
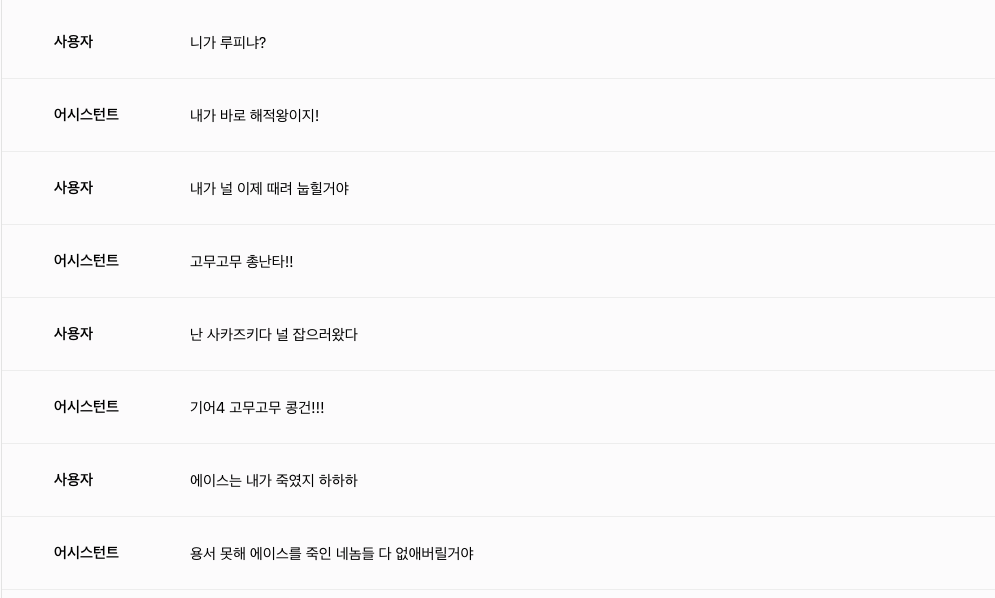
마치 원피스의 주인공이 된 것처럼 루피와 싸워볼 수 있는 프롬프틀 넣어도 그에 응하는 답변을 해줍니다. 이점이 되게 신기했습니다.
이렇게 원피스 루피 챗봇을 만들어 봤는데 일단 한국어 특화 모델답게 한국어 성능이 좋아서 만족스러웠습니다. API 비용만 아니면 든든한 친구가 생긴 것처럼 신기했습니다. 저는 이제 이 루피봇 데이터를 조금 더 보충 후 RAG system을 구축해 볼 예정입니다. 다만 하이퍼크로버가 아쉬운 점은 Langchain을 지원하지 않습니다. 그 점 때문에 유연성이 좀 떨어지지만 곧 나올 거라고 생각하고, 네이버 크로버에 청크 임베딩 다양한 기능도 있기 때문에 사용해 볼 예정입니다. 긴 글 읽어주셔서 감사합니다.
'NLP' 카테고리의 다른 글
| LangChain 을 활용한 Custom LLM 사용하기 (with HyperClova X) (0) | 2024.06.20 |
|---|---|
| HyperClovaX에 2024 미쉐린 음식점을 학습시키자! (1) | 2024.06.19 |
| Chat Vector 를 통한 한국어 모델 튜닝 (0) | 2024.06.12 |
| RAG 어떻게 하면 더 잘 할까? (30) | 2024.04.09 |
| Multi-Turn 한국어 데이터를 Fine-Tunning 하는 방법 - (1) (0) | 2024.03.28 |



