
AI가 바꾸는 스포츠 중계 서비스 혁신: AI 하이라이트/AI 캐스터
devocean.sk.com
위 글을 읽고 너무 재밌고 혁신적인 아이디어라고 생각해서 비슷하게 만들어보았습니다.
옛날부터 Gemini가 멀티모달로 학습을 시켜서 멀티모달의 선두주자 아닌가 생각했었는데, 막상 다른 Claude, ChatGPT 가 텍스트 성능이 워낙 좋다 보니 잘 쓸 기회가 없었습니다. 근데 문득 KT 야구 경기를 보다가 하이라이트가 있는데 이것도 결국 나중에 AI 가 해줄 수 있지 않을까? 생각을 했습니다.
스포츠가 다양하지만 일단 야구와 투수의 삼진으로 좁혀야 개발이 가능할 듯 싶어서, 좁혀서 진행해 보았습니다.
위처럼 사람이 직접 공수를 거쳐서 삼진아웃 전 영상을 클립으로 보통 만드는데 이걸 AI에게 맡겨보자? 이 생각이었습니다. 여러 CV 모델링을 진행해도 되지만, 이건 공수가 너무 들어서 그때 든 생각이 Gemini 너의 긴 Context 라면 가능하지 않겠어? 였습니다.
Gemini Flash
Our lightweight model, optimized for when speed and efficiency matter most, with a context window of up to one million tokens.
deepmind.google
물론 GPT-4o-mini 도 가능할 순 있겠지만 영상의 길이가 길어진다면? 128k로 해결이 가능한가 의문이었고, 100만 토큰이 가능한 새로 나온 Gemini-1.5-flash는 가격도 저렴해지고 속도 또한 빨라졌다고 합니다.
위 링크에 가서 구글클라우드의 Google AI Studio에서 API key를 발급받아야 합니다. 신용카드 결제입력만 하시면 API 키는 발급이 쉽게 가능합니다. api key를 받아와서 입력해 줍니다.
gemini의 큰 강점은 일정량 호출을 무료로 사용해 볼 수 있기 때문에 위와 같은 프로젝트를 할 때 적합합니다. 1.5 pro, 1.5 flash 번갈아서 쓰면 됩니다.
!pip install -q -U google-generativeai
import google.generativeai as genai
import os
API_KEY="your_api_key"
genai.configure(api_key=API_KEY)
video_file = genai.upload_file(path="your video path")
위처럼 apikey 입력을 해주고, 업로드파일을 경로를 지정을 해줍니다. 그리고 genai 아마 클라우드 단으로 업로드를 시키는 것 같습니다. 그렇게 되면 video_file은 하나의 객체가 되어 정보들이 쭉 출력이 됩니다. 이걸로 delete를 할 수 있고 이건 docs에서 확인이 가능합니다.
import time
while video_file.state.name == "PROCESSING":
print('.', end='')
time.sleep(10)
video_file = genai.get_file(video_file.name)
if video_file.state.name == "FAILED":
raise ValueError(video_file.state.name)
정상적으로 업로드가 되어있는지 코드를 수행해 줍니다. 그 후 이미지가 정상으로 업로드가 되어있다면 model을 선언하고, 파라미터는 사용자에 맞게 사용하시면 됩니다. 프롬프트와, videofile 객체를 같이 모델 생성 컨텐트에 인자값으로 넣어주고 리퀘스트 옵션 같은 경우 timeout 초를 설정해서 응답이 600초간 없으면 종료시키는 로직입니다.
prompt = """
동영상 파일에서 타자가 삼진아웃 당하는 장면을 탐지하고, 해당 장면의 시작과 끝 시간을 초 단위로 제공해주세요.
"""
model = genai.GenerativeModel(model_name="gemini-1.5-pro")
print("Making LLM inference request...")
response = model.generate_content([video_file, prompt],
request_options={"timeout": 600})
response.candidates[0].content.parts[0].textGemini의 리스폰은 다음과 같이 출력을 합니다. candidates가 조금 gpt와 다른 모습을 볼 수 있습니다. json 형태로 파싱이 되기 때문에 보시면 금방 아실 수 있습니다.

이런 식으로 결과가 출력이 되는 모습입니다.
이제 이 쿼리를 의미 있게 사용하기 위해선 어떻게 해야 할까 고민을 했습니다. 보통 서비스의 형태로 다양하게 적용할 수 있기 때문에 일단 sql db에 적재를 하자 라는 생각이었습니다. llm에게 db에서 첫 스트라이크장면 주소를 알려줘 한 다음에 바로 실행되게끔 해보자 생각이었습니다.
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import ChatPromptTemplate, HumanMessagePromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List, Tuple
#output 을 어떻게 받을지 설정
class StrikeOutTimes(BaseModel):
strike_out_times: List[Tuple[int, int]] = Field(description="List of strike out time ranges in seconds")
위처럼 pydantic 클래스를 선언해서 outputparser를 Custom으로 만들어주는 코드입니다. 이건 사용자 입맛에 맞게 사용하시면 됩니다. 다른 jsonoutputparser 라던지 llm에게 응답을 고정적인 형태로 뽑고 싶을 때 많이 사용합니다.
def query_llm_for_strike_out_times(result_text, query_llm):
parser = PydanticOutputParser(pydantic_object=StrikeOutTimes)
prompt = ChatPromptTemplate(
messages=[
HumanMessagePromptTemplate.from_template(
"""다음 텍스트에서 타자가 삼진아웃 당하는 시간을 추출하세요:
{result_text}
{format_instructions}
시간은 모두 초 단위로 변환하여 정수로 표현하세요.
지정된 형식으로만 반환하고 다른 설명은 붙이지 마세요."""
)
],
input_variables=["result_text"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
chain = prompt | query_llm | parser
try:
result = chain.invoke({"result_text": result_text})
return result.strike_out_times
except Exception as e:
print(f"Error: LLM 응답을 파싱할 수 없습니다. {str(e)}")
return None
chaining을 통해서 prompt 가 들어가면 outputparser 형태로 호출하게끔 합니다. 제가 원하는 형식은 [(int, int)...] 이런 형식입니다. 이형식을 받아와서 바로 변수에 선언을 할 생각이었습니다. 결국 하나의 동영상에서 시작과 끝 형태의 초로 동영상을 분할을 해줘야 하기 때문입니다.
import cv2
import os
import sqlite3
video_path = "video.mp4"
#위에서 받아온 값
strike_out_times = [
(37, 47),
(60, 68),
(108, 114),
(122, 128),
(132, 137)
]
result_folder = "result"
conn = sqlite3.connect("strike_outs.db")
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS strike_outs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
file_name TEXT,
start_time REAL,
end_time REAL
)
''')
os.makedirs(result_folder, exist_ok=True)
cap = cv2.VideoCapture(video_path)
fps = cap.get(cv2.CAP_PROP_FPS)
for index, (start_time, end_time) in enumerate(strike_out_times):
start_frame = int(start_time * fps)
end_frame = int(end_time * fps)
output_file = os.path.join(result_folder, f"strike_out_{index}.mp4")
out = cv2.VideoWriter(output_file, cv2.VideoWriter_fourcc(*'mp4v'), fps,
(int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))))
cap.set(cv2.CAP_PROP_POS_FRAMES, start_frame)
for frame_num in range(start_frame, end_frame + 1):
ret, frame = cap.read()
if not ret:
break
out.write(frame)
out.release()
cursor.execute('''
INSERT INTO strike_outs (file_name, start_time, end_time)
VALUES (?, ?, ?)
''', (f"strike_out_{index}.mp4", start_time, end_time))
conn.commit()
conn.close()
cap.release()
db를 만들어주고 cursor.execute를 통해 테이블과 피처를 정의해 줍니다. 그 후 반복문이 돌면서 id, 파일주소, 시작, 끝 알맞게 데이터를 저장을 합니다. 그 후 commit, close 하는 형태로 DB를 구성했습니다.
!sqlite3 strike_outs.dbdb의 내부를 확인해 보면 정상적으로 들어가 있습니다.
이제 이 db를 활용한 sql agent를 만들 차례입니다. db 선언은 랭체인 독스를 참고하시길 바랍니다.
SQL Database | 🦜️🔗 LangChain
This notebook showcases an agent designed to interact with a SQL databases.
python.langchain.com
from langchain_community.agent_toolkits import create_sql_agent
from langchain_openai import ChatOpenAI
from langchain_community.utilities.sql_database import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///strike_outs.db")
api_key = "your key"
llm = ChatOpenAI(api_key=api_key,model="gpt-4o-mini", temperature=0)
agent_executor = create_sql_agent(llm, db=db, agent_type="openai-tools", verbose=True)agent 형태가 약간 랭체인에서 gpt를 최적화를 해놔서 gemini로 호출하다가 여러 번 에러가 나길래 그냥 gpt로 하였습니다. 지금 코드를 쭉 읽어보니 agent_type 때문인 거 같은데, react_agent 나 custom 은 가능하니 커스텀해보시길 바랍니다.
agent_executor.invoke(
"첫번째 스트라이크의 파일이름을 알려줘"
)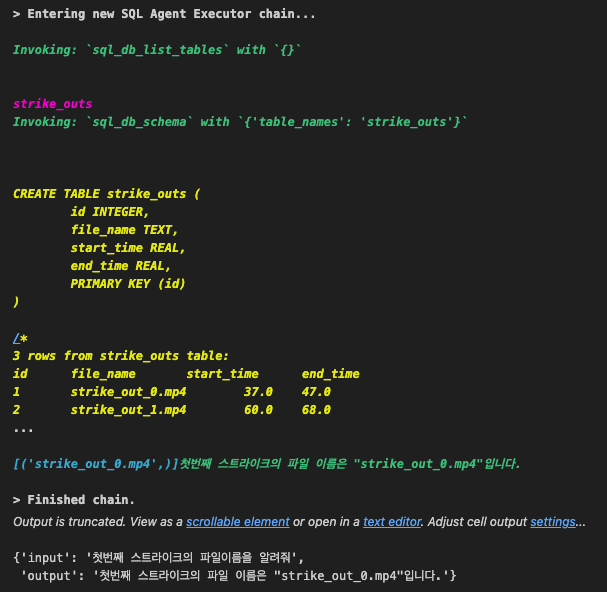
이렇게 비교적 간단한 로직이기 때문에 sql 이 바로 찾아서 알려줍니다. db내용도 잘 나타나있네요.
video_file = "result/"
file_path = video_file + result['output']
cap = cv2.VideoCapture(file_path)
if not cap.isOpened():
print("Error: 동영상을 열 수 없습니다.")
exit()
while True:
ret, frame = cap.read()
if not ret:
print("동영상 재생이 끝났습니다.")
break
cv2.imshow('Video', frame)
if cv2.waitKey(25) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
그다음 opencv 를 통해 파일시스템 주소를 연결해서 동영상을 실행하면 실행이 됩니다. 매우 간단하게 구현을 해봤는데요. 에이닷과 같은 서비스에 붙혀도 되고 서비스를 더 고도화해서 하나의 application 으로 만들어도 됩니다. 정말 AI 가 발전하면서 기획과 어플리케이션을 만드는 능력이 점점 중요해지는구나 계속느끼게되는 프로젝트였습니다
'NLP' 카테고리의 다른 글
| CrewAI 로 LLM Agent 푹 담궈 찍어먹어보기 (0) | 2024.09.04 |
|---|---|
| 실전 데이터를 활용한 LLM Fine-tunning, RAG 적용해보기 (EXAONE Finetuning) - (1) (3) | 2024.08.22 |
| 나혼자 만드는 금융권 LLM Assistant - (1) 페르소나 모델 만들기 (1) | 2024.07.19 |
| HyperClova X 에 LangGraph 적용하기 A to Z (0) | 2024.07.09 |
| HyperClova X 를 통한 RAG 기반 이력서 비서 (0) | 2024.07.01 |



