Attention Mechanism 이란?
어텐션이란? 풀고자 하는 Task의 핵심이 되는 정보를 찾아서 집중한다! 주의 주목, 관심 흥미, 뉴진스 어텐션! 등 다양한 뜻으로 쓰이고 있습니다. 자연어 처리 NLP 분야의 혁신으로 이끈 논문 All yo
hyun941213.tistory.com
Attention mechanism을 돌이켜보며 오늘은 Transformer mechnisim을 알아보겠습니다.
- RNN 계열의 신경망의 순차적 연산은 병렬 연산을 할 수 없도록 한다.
- LSTM, GRU 을 사용한다고 하더라도, 긴 문장에 대해서는 성능이 저하된다.
- 어텐션 메커니즘은 RNN 계열 Seq2 seq 구조에 도입되어 기계번역에 성능을 상당 부분 개선 시킴
그런데 어텐션으로 모든 State를 접근 할 수 있다면 굳이 RNN 이 필요한 건지?(attention is All you Need)
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org

기계 번역을 위해 탄생을 하였고(seq2seq+ attention을 업그레이드) , 번역 작업 때문에 인코더 디코더 구조를 여전히 유지하고 있다.

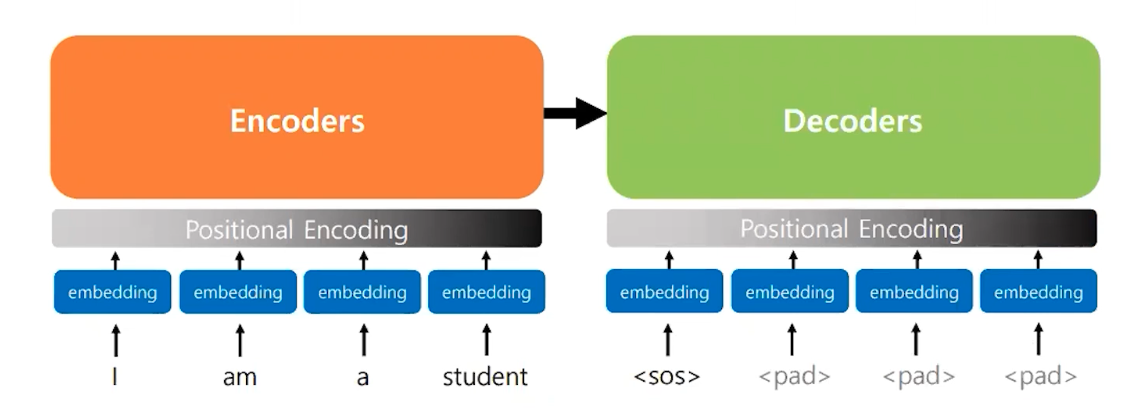
인코더와 디코더 블록(layer)가 N 개가 존재함 , 논문의 경우 6개, 층간의 순차 연산을 한다. RNN처럼 단어를 하나씩 입력받지 않고 단어를 한꺼번에 입력을 받을 수 있다.

- 트랜스포머 다른 립러닝 모델과 마찬가지로 Embedding Layer를 사용한다.
- Embedding Layer를 통해서 얻은 임베딩 벡터를 인코더와 디코더의 입력으로 한다.
- 임베딩 벡터에 Posotional Encoding 이라는 과정을 거친 후에 입력으로 한다.
Positional Encoding : Embbeding Layer 를 거쳐 -> 포지셔널 인코딩을 지나서 모델(입력)로 들어간다.
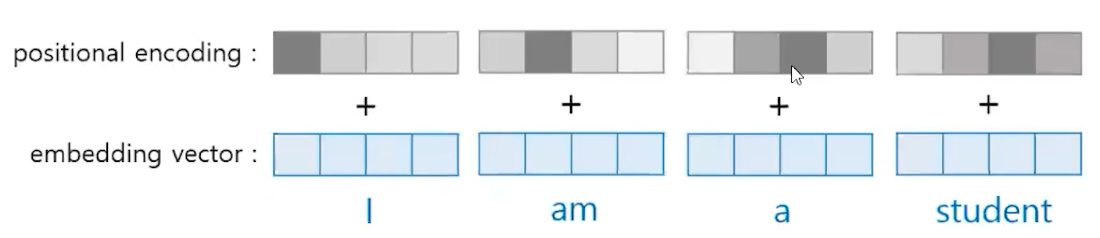

RNN 이 자연어 처리에서 유용했던 이유는 말 그대로 순서대로 입력을 받았었다. 하지만 트랜스포머의 경우 병렬로 문장을 받아들이기 때문

- 짝수위치일땐 sin 함수를 사용하고, 홀수일 때는 cos 함수를 사용한다.

Self-attention 은 문장을 이해하기 위해서 필요하다.
Transformer Encoder
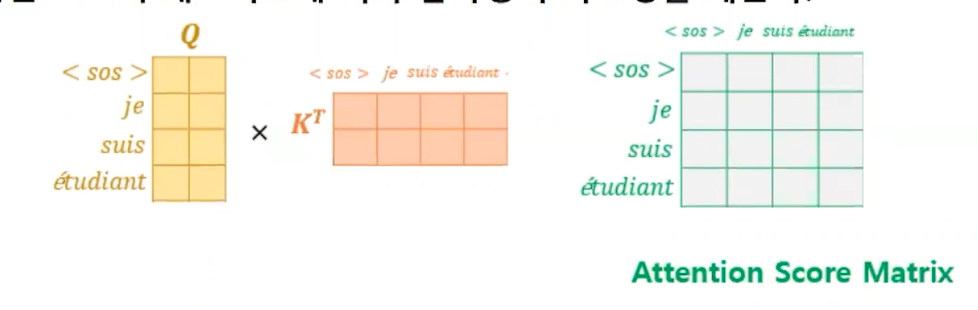
self-attention 행렬 연산

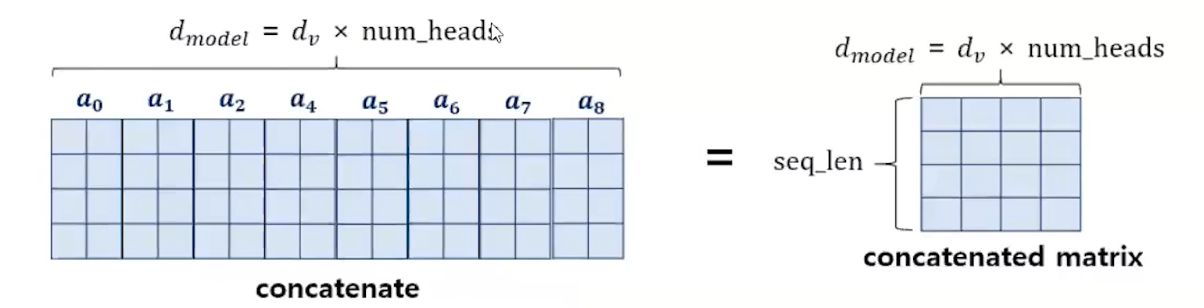
멀티헤드 어텐션은 여러 개의 어텐션 메커니즘(헤드)을 병렬로 사용하여, 각각 다른 부분의 정보를 집중적으로 처리합니다. 이러한 방식으로, 모델은 입력 데이터의 다양한 특징을 동시에 포착하고, 이를 종합적으로 분석하여 더 풍부하고 다면적인 이해를 도모할 수 있다.
512 차원 8개로 나눠서 병렬처리를 해서 다시 콘캣을 해서 다양한 정보를 반영한다.

어텐션이란? 쿼리행렬을 키행렬을 전치해서 곱한 걸 소프트맥스한 가중치를 곱해준다. 멀티헤드어텐션은 헤드개수만큼 concat 해서 연결해서 가중치를 곱해주는 것이다.
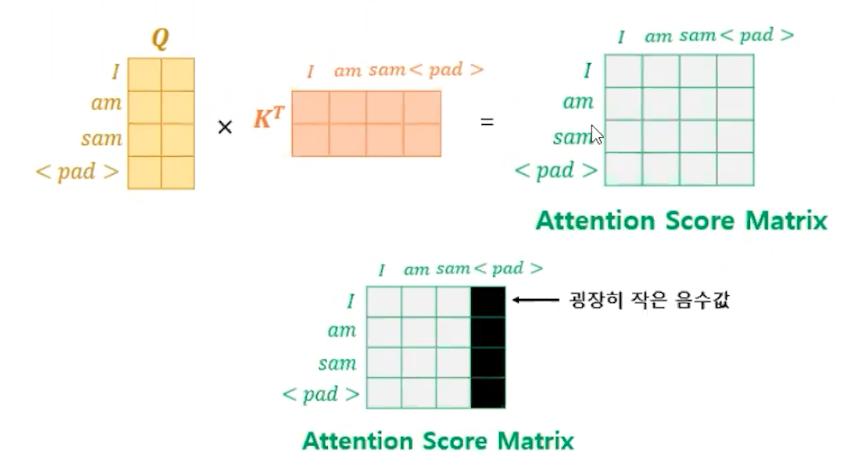
Pad Masking
- 어텐션을 수행할 때, Key에 해당하는 문장에 <pad>가 있는 경우
- 단어 <pad>는 사실 실제 단어가 아니라도 문장의 길이를 맞춰주기 위한 용도이다. <pad>는 어텐션 스코어를 계산하는 일에 불필요하기에 이를 Masking 하는 작업
Position-Wise FFNN
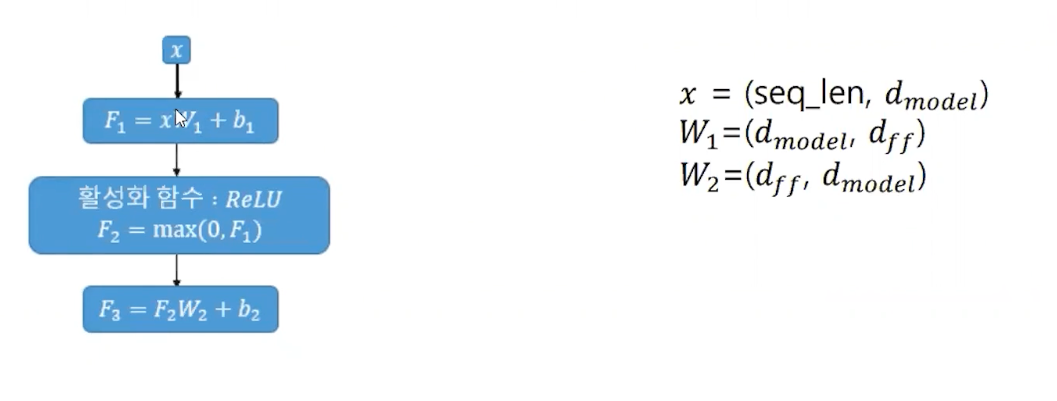
- 포지션 와이즈 피드 포워드 신경망은 단순 피드 포워드 신경망이다.
- 은닉층에서 ReLU 함수를 사용한다. 피드 포워드 신경망의 은닉층의 크기로 논문에서는 2048층이 사용되었다
가중치 행렬을 두 번 통과 시는 구조다. 입력의 크기는 그대로 보존이 된다.
Add(Residual Connection)
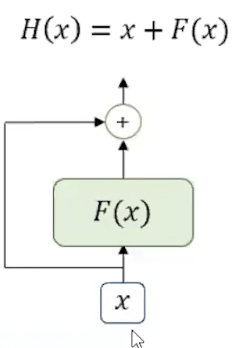
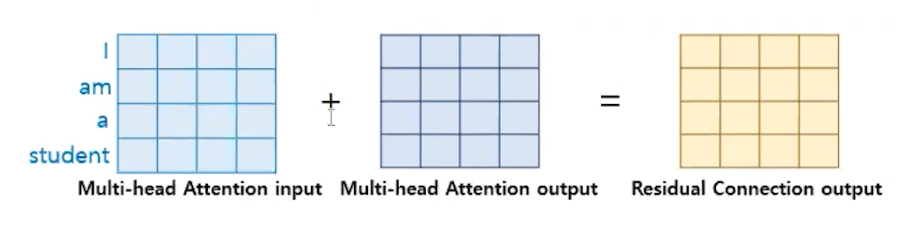
- Residual Connection은 어떤 연산을 한 결과를 연산의 입력과 다시 더해주는 것을 말한다.
- 트랜스포머의 경우 서브층의 연산 결과를 입력과 다시 더해준다.
Norm(Layer Normalization)
Layer normalization 은 텐서의 마지막 차원에 대해서 평균과 분산을 구한다.
tf.keras.layers.LayerNomalization()keras에서 일반적으로 지원해 주는 Nomalization 함수이다.
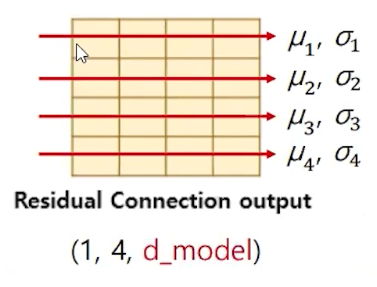
즉, d_model의 평균과 표준 편차를 구하는 것이다. 주요 연산이 끝나면 add + norm을 계속해준다.
Transformer Decoder
Masked Self Attention
트랜스포머 디코더의 Masked Self-attention 은 근본적으로 Self-Attention과 동일하다.
하지만 어텐션 스코어의 매트릭스에 직각 삼각형의 마스킹을 해준다.
Masking 값에는 - 무한대값을 넣어줘서 Softmax에 영향을 끼치지 않도록
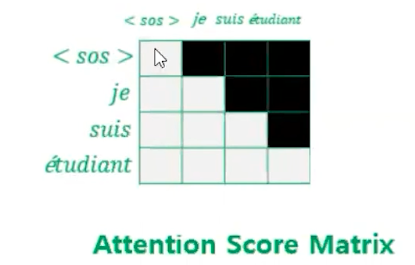
티처 포성이기 때문에 다 넣어줘야 하지만, 테스트할 때 자기 위치 뒤에 있는 애들은 어텐션을 고려하지 않게끔 만들어준다.
디코더의 트랜
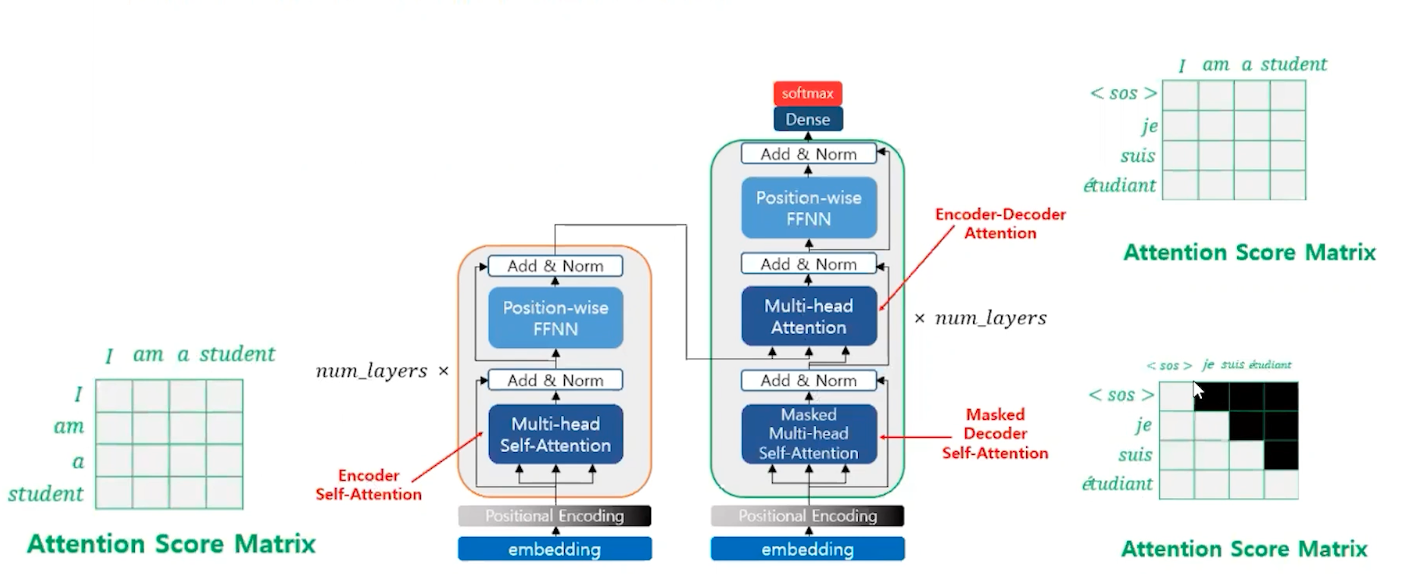
잘 보면 디코더의 멀티헤드 어텐션의 화살표를 주목해 볼 필요가 있다. Query는 Decoder의 값을 가져오고 key, Value는 encoder와 가중치의 곱 add&norm을 지난 값이 온다.
다시 기억!
멀티헤드어텐션 : 쿼리와 키와의 유사도를 구해서 벨류를 반영해 주고 8개를 연결해 주는 방식
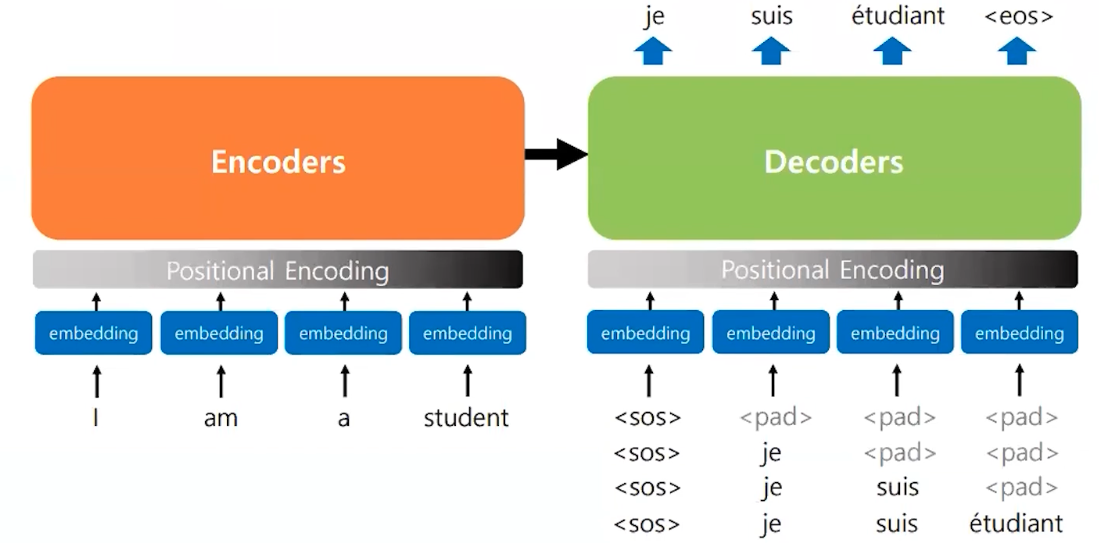
Inference
트랜스포머의 동작방식
test 단계에는 디코더가 단어를 1개씩 생성해내야 한다. 마치 GPT에서 Stream을 쓰는 것처럼
'NLP' 카테고리의 다른 글
| Chat Vector 를 통한 한국어 모델 튜닝 (0) | 2024.06.12 |
|---|---|
| RAG 어떻게 하면 더 잘 할까? (30) | 2024.04.09 |
| Multi-Turn 한국어 데이터를 Fine-Tunning 하는 방법 - (1) (0) | 2024.03.28 |
| Self Consitency prompt (0) | 2024.03.07 |
| Attention Mechanism 이란? (0) | 2024.03.05 |



