안녕하세요 오늘 소개해드릴 논문은 ORPO로 LLAMA3 가 나오고 거의 대부분 Training에 쓰이고 있는 최적화 방법입니다. 놀라운 건 이걸 KAIST에서 발표했네요. 역시 다릅니다.
ORPO: Monolithic Preference Optimization without Reference Model
While recent preference alignment algorithms for language models have demonstrated promising results, supervised fine-tuning (SFT) remains imperative for achieving successful convergence. In this paper, we study the crucial role of SFT within the context o
arxiv.org
GitHub - xfactlab/orpo: Official repository for ORPO
Official repository for ORPO. Contribute to xfactlab/orpo development by creating an account on GitHub.
github.com
Abstract
최근 언어 모델을 위한 선호도 조정 알고리즘들이 희망적인 결과를 보여주고 있지만, 성공적인 수렴을 달성하기 위해서는 감독된 미세조정(Supervised Fine-Tuning, SFT)이 필수적입니다. 본 논문에서는 선호도 조정의 맥락에서 SFT의 중요한 역할을 연구하고, 선호되지 않는 생성 스타일에 대한 경미한 패널티만으로도 선호도 조정된 SFT가 충분하다는 점을 강조합니다. 이를 기반으로, 추가적인 선호도 조정 단계의 필요성을 제거하는 간단하면서도 혁신적인 참조 모델-프리(monolithic) 확률 비율 선호도 최적화 알고리즘인 ORPO를 소개합니다. 125M부터 7B에 이르는 다양한 크기의 모델에서 선호된 스타일과 비선호 스타일을 대조하는 데 확률 비율이 합리적인 선택임을 실증적 및 이론적으로 보여줍니다. 특히, UltraFeedback만을 사용하여 Phi-2(2.7B), Llama-2(7B), Mistral(7B)을 ORPO로 미세조정할 때, 7B 이상 및 13B 이상의 매개변수를 가진 최신 언어 모델의 성능을 초과하는 결과를 달성했으며, AlpacaEval2.0에서 최대 12.20%, IFEval(명령 수준에서 느슨한)에서 66.19%, 그리고 MT-Bench에서 7.32의 결과를 보였습니다. Mistral-ORPOα(7B)와 Mistral-ORPO-β(7B)의 코드와 모델 체크포인트를 공개합니다.
1 Introduction

다양한 자연 언어 처리(NLP) 작업에서 뛰어난 능력을 보여주는 웹 텍스트나 교과서와 같은 방대한 훈련 데이터를 사용하여 사전 훈련된 언어 모델(PLMs)이 개발되었습니다. 그러나 이 모델들은 일반 도메인 응용 프로그램에서 사용하기 위해 추가 튜닝이 필요하며, 일반적으로 지시사항 튜닝과 선호도 조정과 같은 과정을 거칩니다. 지시사항 튜닝은 모델이 자연어로 제공된 작업 설명을 따르도록 훈련시켜, 이전에 보지 못한 작업에도 잘 일반화할 수 있게 합니다. 그러나 지시사항을 따를 수 있는 능력에도 불구하고, 모델은 유해하거나 비윤리적인 결과를 생성할 수 있습니다. 이러한 모델들을 인간의 가치와 더욱 일치시키기 위해서는 강화 학습을 통한 인간의 피드백과 직접 선호도 최적화 기법을 사용하여 페어와이즈 선호도 데이터로 추가 훈련이 필요합니다. 선호도 조정 방법은 해를 줄이는 것을 넘어서 사실성 향상, 코드 기반 질문 답변, 기계 번역 등 여러 하류 작업에서 성공을 입증했습니다. 본 논문에서는 모델 조정을 위한 새롭고 단순한 일체형 조정 방법, 확률 비율 선호도 최적화(ORPO)를 제안하며, 이 방법은 SFT 동안 원치 않는 생성 스타일을 학습하는 것으로부터 모델을 효율적으로 처벌합니다. 이 접근 방식은 이전의 연구와 달리 SFT 예열 단계나 참조 모델을 필요로 하지 않으며, 선호도 기반 조정 모델의 자원 효율적인 개발을 가능하게 합니다. ORPO로 Phi-2 (2.7B), Llama-2 (7B), Mistral (7B)을 미세조정한 결과와 다양한 데이터셋과 모델 크기에 대해 ORPO를 기존 모델 조정 방법과 비교한 제어 실험 결과를 보여줍니다. 또한, 이론적, 실증적, 계산적 근거를 통해 일체형 선호도 조정에서 확률 비율을 활용하는 것의 정당성을 설명합니다. Mistral-ORPO-α (7B)와 Mistral-ORPO-β (7B) 모델의 훈련 코드와 체크포인트를 공개하며, 이 모델들은 각각 MT-Bench에서 7.24와 7.32, AlpacaEval2.0에서 11.33%와 12.20%, IFEval 지시 수준 느슨한 정확도에서 61.63%와 66.19%의 성과를 달성했습니다.

RLHF는 리워드모델, Ref, Policy -> DPO 는 Reward를 개선했지만 여전히 데이터셋을 사람이 선호하는 Chosen / rejected를 통해 훈련을 하는데, ORPO는 두 가지 접근방법을 간소화해서 단일 단계로 모델을 조정하는 듯하다. 선택된 응답에 대한 강한 적응 신호와 거절된 응답에 대한 약한 페널티를 적용하여 단순 로그 확률 용어를 부정 로그 우도 손실에 추가함으로 구성이 되어있다. 수식을 보면 이해가 좀 더 쉽다. 결국 로스함수에서 확률 비율을 추가해서 페널티를 부과하고, 모델이 선호도를 반영하도록 조정하는 것이다.
2 Related Works
언어 모델의 선호도 조정과 관련된 다양한 접근 방법들에 대해 논의합니다. 인간의 피드백을 사용한 강화 학습(RLHF)은 Bradley-Terry 모델을 적용하여 독립적으로 평가된 두 인스턴스 간의 경쟁 확률을 추정합니다. 보상 모델을 훈련시켜 인스턴스를 점수화하고, PPO와 같은 강화 학습 알고리즘을 사용하여 보상 모델의 점수를 최대화하는 응답을 생성하도록 모델을 훈련합니다. 그러나 RLHF는 PPO의 불안정성과 보상 모델의 민감성으로 인해 방대한 하이퍼파라미터 탐색의 어려움에 직면하고 있습니다. 보상 모델 없이 선호도 조정을 수행하는 여러 기술이 제안되었습니다. Rafailov et al. (2023)은 보상 모델링 단계를 선호도 학습 단계와 결합하는 DPO를 소개했으며, IPO를 통해 DPO의 과적합 문제를 방지합니다. 또한 RLHF와 DPO와 달리 페어와이즈 선호도 데이터셋이 필요 없는 KTO와 ULMA가 제안되었습니다. 또한, Song et al. (2023)은 음의 로그 우도 손실에 참조 응답 세트의 소프트맥스 값을 포함시켜 감독된 미세 조정과 선호도 조정을 통합하도록 제안합니다. 강화 학습에서 선호도 조정 방법은 SFT를 이용하여 활성 정책의 안정적인 업데이트를 보장합니다. 그러나 선호도 조정을 SFT에 통합하는 실제 역할과 이론적 배경은 아직 충분히 연구되지 않았습니다.
3 The Role of Supervised Fine-tuning
선호도 조정 방법의 초기 단계로서 감독된 미세조정(SFT)의 행동을 SFT의 손실 함수 분석과 훈련된 SFT 모델의 선호도 이해 능력에 대한 실증적 증거를 통해 연구합니다. SFT는 관련 토큰의 로그 확률을 증가시킴으로써 사전 훈련된 언어 모델을 원하는 도메인에 맞게 조정하는 데 중요한 역할을 합니다. 그러나 이 과정에서 원하지 않는 스타일의 토큰 생성 가능성 또한 무심코 증가시키게 됩니다. 따라서 SFT의 도메인 적응 역할을 유지하면서 동시에 원치 않는 생성 스타일을 식별하고 완화하는 능력을 가진 방법을 개발할 필요가 있습니다.
Absence of Penalty in Cross-Entropy Loss
크로스 엔트로피 손실은 모델 미세 조정의 목적으로, 참조 답변에 대한 예측된 로짓이 낮을 경우 모델을 처벌하기 위해 사용됩니다.
즉 우리가 일반적으로 쓰는 로스 함수는 원하는 답변을 잘 생성하도록 모델을 가이드하지만, 원하지 않는 답변을 생성할 때 적절히 조정하는 메커니즘이 부족하다는 것이다.

- L은 손실 함수의 값입니다.
- m은 데이터 세트 내의 샘플 수입니다.
- V는 모델의 어휘(vocabulary) 집합이며, |V|는 어휘 집합의 크기(즉, 전체 단어의 수)를 의미합니다.
- k는 특정 샘플을 나타내며, m개의 샘플 각각에 대해 계산을 반복합니다.
- y_i^(k)는 실제 데이터에서 k번째 샘플에 대해 i번째 단어가 타겟 단어일 때 1이고, 그렇지 않으면 0입니다.
- p_i^(k)는 모델이 k번째 샘플에서 i번째 단어를 타겟 단어로 예측할 확률입니다.
- log는 확률을 구하기 위한 자연로그
yi가 1과 0 인경우라고 했을때 0인경우, log 확률이 계산이 포함이 안되기 때문에 1인경우 더 높은 확률을 의 log 값을 전달할 수 있지만, 1이 아닌 경우에는 아무것도 feedback을 주지 않는다는 점입니다. 결국 선호도 조정의 관점에서는 원하지 않는 결과라고 볼 수 있다.
Generalization over Both Response Styles We
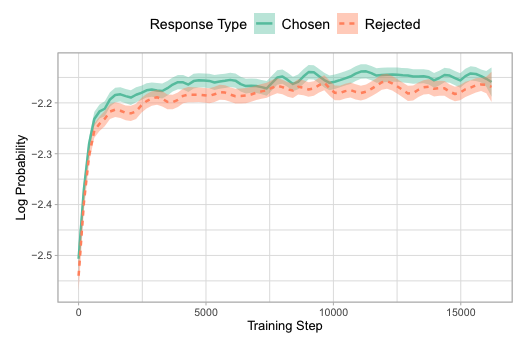
감독된 미세조정만으로 선택된 응답과 거부된 응답에 대한 보정 불일치를 실증적으로 보여주는 예비 연구를 수행한다고 설명합니다. OPT-350M 모델을 HH-RLHF 데이터셋의 선택된 응답으로만 미세조정하면서, 훈련하는 동안 각 배치에 대한 거부된 응답의 로그 확률을 모니터링하고 이를 그림 3에 보고합니다. 선택된 응답과 거부된 응답의 로그 확률이 동시에 증가하는 것이 관찰되었습니다. 이는 두 가지 관점에서 해석할 수 있습니다. 첫 번째로, 크로스 엔트로피 손실은 모델을 의도된 도메인(예: 대화)으로 효과적으로 유도하지만, 원치 않는 생성물에 대한 페널티가 없기 때문에 거부된 응답이 선택된 응답보다 더 높은 로그 확률을 가질 때가 있습니다. 이 내용은 모델이 원하는 스타일의 응답뿐만 아니라 원치 않는 스타일의 응답도 동시에 잘 생성할 가능성이 있다는 것을 시사합니다. 특히 감독된 미세조정을 통해서만 학습을 진행할 때, 모델이 바람직하지 않은 응답을 생성하는 것에 대해 적절히 처벌하지 못함으로써, 원하지 않는 응답이 선택된 응답만큼의 높은 확률을 가질 수 있음을 나타냅니다. 이러한 결과는 선호도 조정 방법에서 거부된 응답에 대한 보정을 보다 잘 다루는 방법이 필요함을 시사합니다
위 실험에서, 두가지 Chosen과 Reject가 로그확률이 같이 증가하는 것이 관찰되었고, 페널티가 없기 때문에 너무 일반적으로 다 대답하는 모델이 만들어지는 것이란 것 같다. 결국 거부된 응답에 대한 조치가 필요해 보인다고 말하는 듯하다.
Penalizing Undesired Generations
원하지 않는 생성물에 대해 페널티를 부여하는 것에 관해 설명하고 있습니다. 손실 함수에 'unlikelihood penalty'를 추가하는 방식이 모델에서 원치 않는 특성을 감소시키는 데 성공적이었다고 합니다. 예를 들어, 반복을 방지하기 위해 최근 콘텍스트에서 사용된 원하지 않는 토큰 세트 𝑘∈는 손실에 다음 항을 추가하여 불리하게 만듭니다. 이 항은 모델이 최근 토큰에 높은 확률을 할당하는 것에 대해 모델을 처벌합니다. 이는 (1 − p_i^(k))의 형태로 손실에 추가됩니다(예: 식 2와 같은). 감독된 미세조정(SFT)에서 거부된 토큰에 높은 확률을 부여하는 경향(그림 3 참조)과 원하지 않는 특성에 대한 페널티를 추가하는 것의 효과성에 동기를 얻어, 거부된 토큰의 세트를 만드는 것 없이 각 쿼리에 대해 불리한 응답에 동적으로 페널티를 부여하는 일체형 선호도 조정 방법을 설계합니다.
위에서 말한 대로 언어모델이 바람직하지 않은 출력을 줄이기 위해 새로운 조정방법을 제안하고 있다. 손실함수에 페널티 항을 추가하는 방식으로 Reject를 높은 확률을 할당하지 않도록 유도, 지시하여 바람직하지 않은 언어적 특성을 갖는 응답의 가능성을 줄이는 것이다.
4 Odds Ratio Preference Optimization
새로운 선호도 조정 알고리즘인 확률 비율 선호도 최적화(ORPO)를 소개합니다. 이 방법은 좋아하는 응답과 그렇지 않은 응답 사이의 생성 스타일을 구분하기 위해 전통적인 음의 로그 우도(Negative Log-Likelihood, NLL) 손실에 확률 비율 기반의 페널티를 통합합니다. 이로 인해 모델이 불리한 응답을 생성하는 것에 대해 페널티를 받게 되며, 선호하는 응답 스타일을 더 잘 학습하게 됩니다. 이러한 조정은 모델이 선호도에 맞춰 더 정교하게 반응할 수 있도록 돕습니다.
4.1 Preliminaries (기초):
입력 시퀀스 x가 주어졌을 때, m 토큰의 길이를 갖는 출력 시퀀스 y를 생성하는 평균 로그 가능도는 식 3으로 계산됩니다. 주어진 입력 x에 대해 출력 시퀀스 y를 생성할 확률의 비율(odds)은 식 4로 정의됩니다.
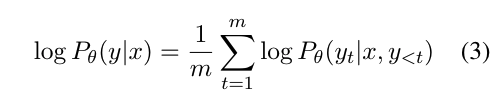
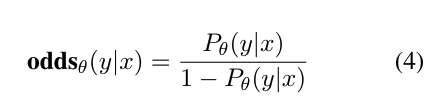
[x는 입력 시퀀스, y는 출력 시퀀스]
Odds0(y|x)는 주어진 x에 대해 y를 생성할 확률이다. 분자는 모델 θ가 입력 x를 받았을 때 출력 y를 생성할 확률이다. 분모는 모델 θ가 y를 생성하지 않을 확률이다. 결국 특정 x가 들어가면 y가 나올 확률이 안 나올 확률보다 높다는 얘기다
직관적으로, oddsθ(y|x) = k는 모델 θ가 출력 시퀀스 y를 생성할 확률이 그것을 생성하지 않을 확률보다 k배 더 높다는 것을 의미합니다. 선택된 응답 yw에 대한 거부된 응답 yl의 확률 비율, ORθ(yw, yl), 은 주어진 입력 x에 대해 모델 θ가 yl보다 yw를 생성할 확률이 얼마나 더 높은 지를 나타냅니다(식 5 참조).
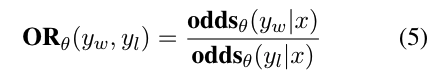
Yw(Chosen), Yl(Rejected)이 되기 때문에 이 비율이 1보다 크다면, Chosen 이 더 자주 생성 될 것으로 기대할 수 있다.
4.2 Objective Function of ORPO (목적 함수):
ORPO의 목적 함수는 식 6에 나와 있으며, 두 부분으로 구성됩니다:
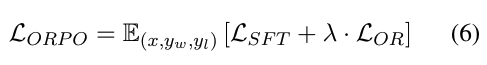
1) 감독된 미세조정(SFT) 손실 (LSFT); 2) 상대 비율 손실 (LOR). LOR는 식 7에 있는데, 이는 거부된 응답 yl과 선택된 응답 yw 사이의 확률 비율을 최대화합니다. 로그 시그모이드 함수로 로그 확률 비율을 감싸서 LOR를 yw와 yl 사이의 로그 확률 비율을 증가시키면서 최소화할 수 있도록 합니다.
LSFT와 λ로 가중된 LOR는 함께, 사전 훈련된 언어 모델을 특정 도메인의 부분집합에 맞게 적응시키고 거부된 응답 세트의 생성물을 불리하게 만듭니다.
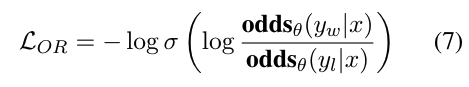
6 번식은 OPRO의 전체 목적 함수로 SFT 미세조정으로 손실과 시그모이드를 통해서 or을 계산해서 선택과 거부의 값을 더하는 식이다.
7번은 음의로그우도 방식에 따라 -log 시그모이드를 태워 확률로 변환시키고 오즈비율이 클수록 작은 손실을 반환한다. 이렇게 해서 선호하는 응답을 생성할 확률을 높이는 방법으로 학습을 시키기 위함이다.
4.3 Gradient of ORPO (기울기):
LOR의 기울기는 확률 비율 손실을 사용하는 것이 정당하다는 것을 추가적으로 입증합니다. 이는 잘못된 예측에 대해 처벌하는 항과 선택된 응답과 거부된 응답 사이의 대조를 나타내는 두 가지 항으로 구성됩니다(식 8 참조).
선택된 응답의 확률이 거부된 응답보다 상대적으로 높을 때, 식 9의 δ(d)는 0으로 수렴하게 됩니다. 이는 δ(d)가 페널티 항으로서 역할을 하여, 모델이 거부된 응답을 생성할 확률이 높을 경우 매개변수 업데이트를 가속화할 것임을 나타냅니다.
한편, 식 10의 h(d)는 선택된 응답과 거부된 응답에서 나오는 두 기울기의 가중 대조를 의미합니다. 구체적으로, 분모에 있는 1−P(y|x)는 해당되는 측의 가능도 P(y|x)가 낮을 때 기울기를 증폭시킵니다. 선택된 응답에 대해서는, 가능도가 증가함에 따라 모델이 선택된 응답의 분포에 더 빨리 적응하도록 가속화합니다.
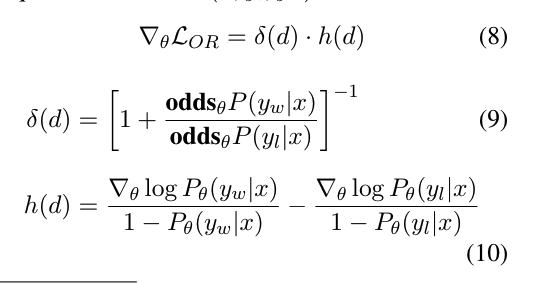
모델 학습 과정에서 선택된 응답을 더 선호하게 하고, 거부된 응답에 대한 가능성을 줄이기 위해 모델 파라미터를 어떻게 조정할지 계산하는 데 필요한 구성 요소들을 정의한다. 결국 이 과정은 모델이 선호되는 응답의 분포를 더 잘 학습하고, 거부된 응답을 피하도록 유도하는 데 도움을 준다.
5 Experimental Settings
논문 본문을 참고해 주길 바랍니다.
6 Result and Analysis
6.1 Single-turn Instruction Following
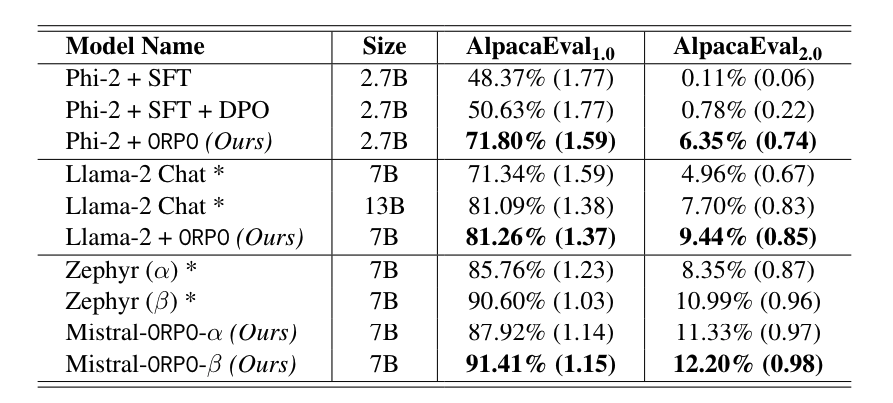
Phi-2 (2.7B) 모델은 ORPO를 사용하여 UltraFeedback 데이터셋으로 미세조정되어 Llama-2 챗 모델보다 더 높은 성능을 보였습니다. ORPO 모델은 AlpacaEval에서 71.80%의 결과를 얻었습니다. Llama-2 (7B) 모델도 ORPO를 사용하여 81.26%의 AlpacaEval 점수를 달성했습니다.
6.2 Multi-turn Instruction Following
ORPO로 미세조정된 Mistral-ORPO-α (7B)와 Mistral-ORPO-β (7B) 모델은 MT-Bench를 통해 다중 턴 지시-추종 능력을 평가했으며, 대규모 또는 독점적 모델들과 비교할 때 비슷한 성능을 보였습니다.
6.3 Reward Model Win Rate
ORPO가 다른 정렬 방법들, 즉 SFT, PPO, DPO와 비교하여 더 높은 승률을 보이는지 평가했습니다. ORPO는 데이터 질의 영향을 받아 AlpacaEval에서 91% 이상의 승률을 보이며, 데이터셋의 질이 높을수록 성능이 향상되었습니다.
HH-RLHF 데이터셋에 대한 ORPO의 승률 평가:
- 모든 모델 규모에서 ORPO는 SFT와 PPO보다 더 높은 승률을 기록했습니다.
- 가장 큰 모델에서는 SFT에 대해 78.0%, PPO에 대해 79.4%의 승률을 달성했습니다.
- 모델의 크기에 따라 DPO에 대한 승률이 증가했으며, 가장 큰 모델이 70.9%의 가장 높은 승률을 기록했습니다.
UltraFeedback 데이터셋에 대한 ORPO의 승률 평가:
- UltraFeedback에서의 승률도 HH-RLHF에서의 트렌드와 유사했습니다.
- ORPO는 SFT와 PPO에 비해 최대 80.5%와 85.8%의 선호도를 보였습니다.
- ORPO는 모델 크기가 커질수록 DPO에 대한 승률이 점차 증가했습니다.
보상 분포 평가:
- 승률뿐만 아니라, ORPO로 생성된 응답의 보상 분포도 평가했습니다.
- SFT의 보상 분포를 기준으로, PPO, DPO, ORPO는 두 데이터셋 모두에서 보상 분포를 이동시켰습니다. 그러나 각 알고리즘에 따른 보상 변화의 정도는 달랐습니다.
8 Conclusion
이 연구에서는 선호도 조정의 맥락에서 감독된 미세조정(SFT) 단계의 가치를 제고하고 이해함으로써 참조 모델이 필요 없는 일체형 선호도 조정 방법인 확률 비율 선호도 최적화(ORPO)를 소개했습니다. ORPO는 다양한 크기의 모델에 대해 감독된 미세조정(SFT)과 강화 학습 기반의 인간 피드백(RLHF)에 비해 일관되게 선호되었으며, 모델의 크기가 커질수록 직접 정책 최적화(DPO)에 대한 승률이 증가했습니다. 또한, ORPO는 AlpacaEval에서 최신 상태의 대형 지시-추종 언어 모델들을 능가하며 2.7B 및 7B 사전 훈련된 언어 모델들의 확장성을 입증했습니다. 특히 Mistral-ORPO-α와 Mistral-ORPO-β는 AlpacaEval2.0에서 각각 11.33%와 12.20%, MT-Bench에서 7.23과 7.32의 성과를 달성하였습니다. 이러한 결과들은 ORPO의 효율성과 효과성을 강조합니다. 연구의 재현성을 돕기 위해 Mistral-ORPO-α와 Mistral-ORPO-β의 미세조정 코드와 모델 체크포인트를 공개했습니다.
Code
ORPO 트레이너는 DPO 트레이너와 동일한 형식을 요구하며, 여기에는 세 개의 항목이 포함되어야 합니다. 이러한 항목의 이름은 다음과 같아야 합니다:
prompt
chosen
rejected
딕셔너리 형태의 데이터셋을 구성해 주고 key에는 prompt, chosen, rejected가 들어가고, 각각 query, 선호내용, 비선호내용이 들어가게 됩니다.
orpo_dataset_dict = {
"prompt": [
"hello",
"how are you",
"What is your name?",
"What is your name?",
"Which is the best programming language?",
"Which is the best programming language?",
"Which is the best programming language?",
],
"chosen": [
"hi nice to meet you",
"I am fine",
"My name is Mary",
"My name is Mary",
"Python",
"Python",
"Java",
],
"rejected": [
"leave me alone",
"I am not fine",
"Whats it to you?",
"I dont have a name",
"Javascript",
"C++",
"C++",
],
}
ORPOTrainer 사용
자세한 예제는 examples/scripts/orpo.py 스크립트를 참조하세요. 높은 수준에서는 학습하고자 하는 모델로 ORPOTrainer를 초기화해야 합니다. ORPOTrainer를 사용하면 참조 모델을 사용할 필요가 없으므로 최적화 프로세스가 간소화됩니다. 베타는 논문 식 (6)의 하이퍼파라미터 람다를 의미하며, SFT에 사용되는 표준 교차 엔트로피 손실에서 상대 홀수 비율 손실의 가중치를 나타냅니다.
orpo_config = ORPOConfig(
beta=0.1, # the lambda/alpha hyperparameter in the paper/code
)
orpo_trainer = ORPOTrainer(
model,
args=orpo_config,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
orpo_trainer.train()LLama3을 활용한 ORPO 튜닝
llama3을 바로 ORPO를 적용해서 학습을 하는 예제가 많이 나오고 있다.
Fine-tune Llama 3 with ORPO
Fine-tune Llama 3 with ORPO ORPO is a new exciting fine-tuning technique that combines the traditional supervised fine-tuning and preference alignment stages into a single process. This reduces the computational resources and time required for training. Mo
huggingface.co
DPO 데이터셋을 사용해서 튜닝을 해도 될듯하다.
dataset_name = "mlabonne/orpo-dpo-mix-40k"
dataset = load_dataset(dataset_name, split="all")
dataset = dataset.shuffle(seed=42).select(range(1000))
def format_chat_template(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
dataset = dataset.map(
format_chat_template,
num_proc= os.cpu_count(),
)
dataset = dataset.train_test_split(test_size=0.01)
Llama3의 chat_template
#single
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
#multi
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message_1 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1 }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_message_2 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
orpo params
다른 SFT와 거의 다를 게 없어 보인다. beta 파라미터만 추가하고, 학습을 시키는 것으로 보인다.
orpo_args = ORPOConfig(
learning_rate=8e-6,
beta=0.1, #orpo lambda
lr_scheduler_type="linear",
max_length=1024,
max_prompt_length=512,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
optim="paged_adamw_8bit",
num_train_epochs=1,
evaluation_strategy="steps",
eval_steps=0.2,
logging_steps=1,
warmup_steps=10,
report_to="wandb",
output_dir="./results/",
)
trainer = ORPOTrainer(
model=model,
args=orpo_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
peft_config=peft_config,
tokenizer=tokenizer,
)
trainer.train()
trainer.save_model(new_model)
초간단 코드였다. 결국 데이터셋이 문제인데 그냥 DPO 데이터셋 가져다 쓰고 Chat_template 만 맞춰주면 될 것 같다.



