
정말 오랜만에 글을 쓰게 되었습니다. 너무 재밌어 보이는 모델 Nova가 나와서 이건 ~ 못 참지 하면서 달려왔습니다. AWS 도 Claude에 전략적인 투자를 하고 있어서 자체 LLM을 만드냐 안 만드냐 말이 많았는데, AWS Re:invent에서 'Nova'라는 재미있는 모델을 내놓았습니다. 간단하게 노바에 대해 설명드리면 Tier 별로 나눠져 있지만 한 줄로 GPT-4o 성능인데 가격이 75% 저렴하다!

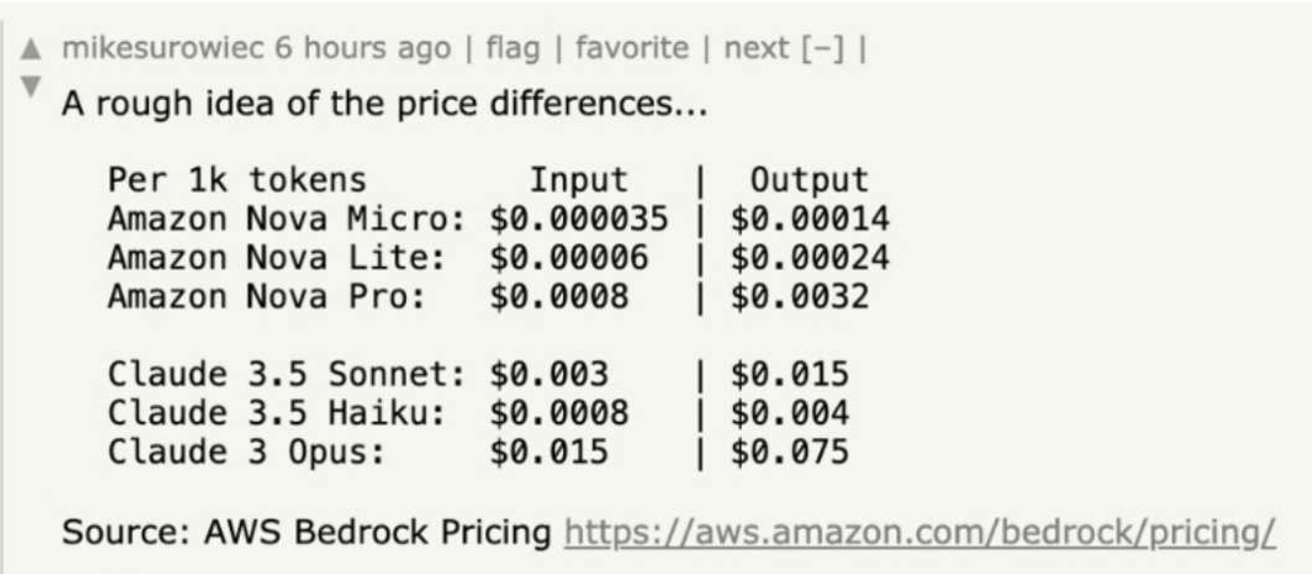
재밌는점은 Premier 상위 모델이 안 나왔다는 점입니다. 일단 프런티어 모델들의 흐름은 이미 학습은 충분하고 추론 과정에서 CoT와 같은 효율적인 리즈닝과정을 거쳐서 답변을 최적화로 뽑는 형태로 많이 빅테크들이 전환을 하고 있는데, 아마 Premier 도 gpt-o1처럼 그런 느낌의 모델이 아닐까 생각이 듭니다. 역시 클라우드 1위 업계이긴 한데.. 그럼 Claude는..? 이란 생각이 들긴 했습니다. 내년에는 멀티모달 'Any-to-Any' 형태로 모델을 공개한다고 하니.. 제 생각이 딱 맞아떨어졌습니다. 2022 GPT!! 2023 RAG!! 2024 Agent!! 2025 Multi-Modal!! 느낌입니다. 미리 미리 멀티모달을 응용한 서비스들을 많이 개발해봐야겠습니다.

회사에서 AWS 자격증을 따라고 했어서 만든 줄 알았는데 회사메일로 가입을 해서 계정이 없어서 가입을 했습니다. 사실 AWS가 오픈소스기반의 RAG 생태계를 잘 구현하는 것 같습니다. 물론 자기들의 설루션을 쓰는 것을 기준이지만, 링크드인의 aws SA 분들 글을 보면 정말 배울 점이 많습니다.
먼저 AWS 계정을 가입 후 프리티어로 진행을 합니다. 이 과정에서 신용카드 Credit 등록을 해야 하니 신용카드 지참해 주세요. 그 후 IAM에 들어가서 권한설정을 해야 하는데 그룹 -> 사용자 차례대로 설정을 진행을 해주고, 루트 계정을 사용하지 말고 새로 발급받은 예로 'KDB' 계정을 활성화해서 사용합니다. 권한 설정을 줄 때 Amazon Bedrock Full access를 해주시기 바랍니다.
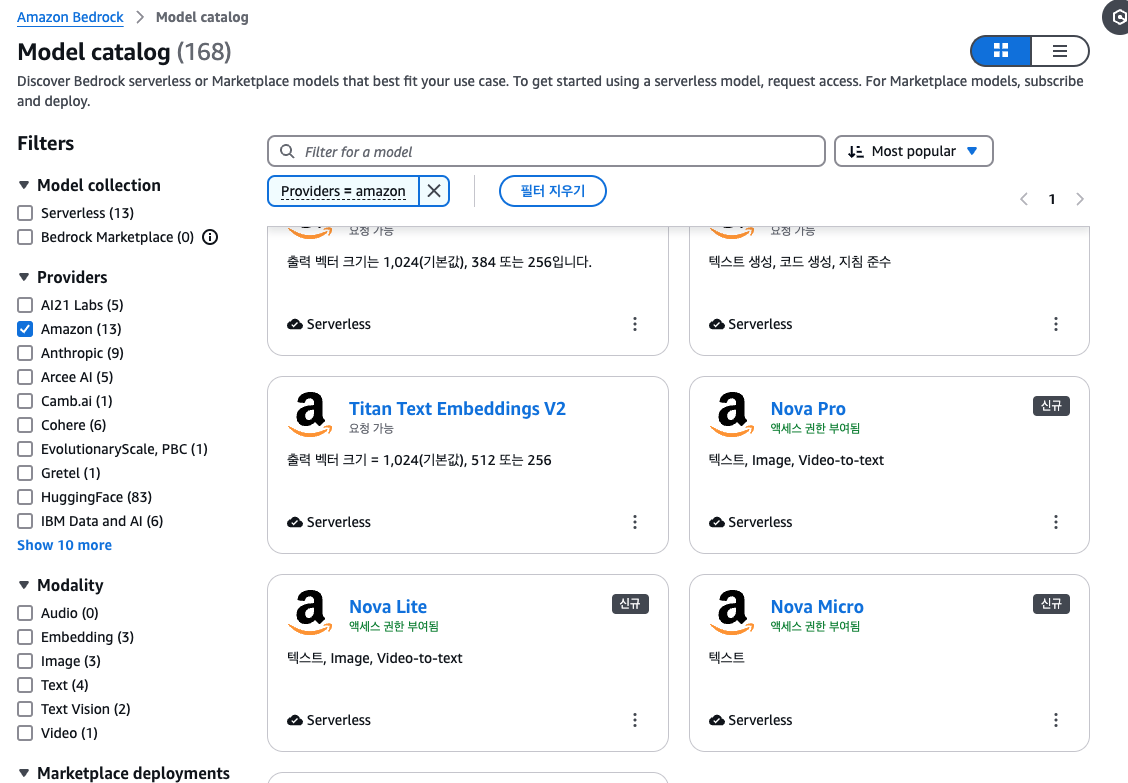
Amazone Bedrock으로 들어간 후 모델 카탈로그에서 Nova 모델의 권한을 허용해 줍니다. 베드락을 보면서 Amazon 이 LLM을 활용하여 Application을 만드는데 정말 진심이구나 느껴졌던 게 여러 Opensource 모델들도 되고, jamba도 있었습니다. Claude도 방법은 동일합니다 위와 같이 설정해 주면 됩니다.
계정 보안자격증명 탭을 누르고, 작업을 위한 액세스 키를 발급을 받아줍니다. 그럼 Access key, Secret Key 2개가 나오게 되고 잘 적어둡니다. 퍼블렉시티에게 물어보니, 일단 한국 리전은 지원하지 않습니다. 일반적으로 us-east-1로 사용하니 이걸 기억해 주고

import boto3
# AWS 자격 증명 설정
aws_access_key_id = "your key"
aws_secret_access_key = "your key"
# STS 클라이언트 생성
sts = boto3.client(
'sts',
region_name='us-east-1',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
# 자격 증명 테스트
try:
response = sts.get_caller_identity()
print("자격 증명 확인 성공:", response)
# Bedrock 클라이언트도 생성해서 테스트
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-east-1',
aws_access_key_id=aws_access_key_id,
aws_secret_access_key=aws_secret_access_key
)
print("Bedrock 클라이언트 생성 성공")
except Exception as e:
print("자격 증명 오류:", str(e))
boto3을 pip 설치해 주고 위코드를 통해서 자격증명오류가 제대로 나오는지 확인을 합니다. 여기서 만들어진 bedrock_runtime 은 Client 객체로 넘어가서 langchain에서 활용하게 됩니다.
ChatBedrock | 🦜️🔗 LangChain
This doc will help you get started with AWS Bedrock chat models. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and
python.langchain.com
간결하게 테스트 코드를 작성해 봅니다.
from langchain_aws import ChatBedrock
llm = ChatBedrock(
model_id="amazon.nova-pro-v1:0",
client=bedrock_runtime,
streaming=True,
model_kwargs={
"temperature": 0.7,
"max_tokens": 1000
}
)
def chat_with_model(prompt: str):
messages = [
{
"role": "user",
"content": prompt
}
]
try:
response = llm.invoke(messages)
print("응답:", response.content)
except Exception as e:
print("오류 발생:", str(e))
# 테스트
chat_with_model("AWS란 무엇인가요? 간단히 설명해주세요.")
LLM 준비는 끝이 났고 이제 유기적으로 LangChain LLM으로 활용하면 됩니다.
리팩토링
LinkedIn 김재현 페이지: 가짜연구소 9th - GJS "Stockelper" 📈 🦜🕸️ LangGraph 를 활용한 주식종목 매
가짜연구소 9th - GJS "Stockelper" 📈 🦜🕸️ LangGraph 를 활용한 주식종목 매수/매도 추천 프로세스 제어와 일상 대화 봇 제작기 1. 사용자 쿼리가 들어오면 주식관련 / 일상질문 인지 LLM 이 판단제어
kr.linkedin.com
GitHub - jh941213/Stockelper_nasdaq: 가짜연 9th 깃허브 잔디심기 Stockelper
가짜연 9th 깃허브 잔디심기 Stockelper . Contribute to jh941213/Stockelper_nasdaq development by creating an account on GitHub.
github.com
이미 게시를 하긴 했었는데, 나스닥 기반의 Symbol을 추출해서 기존의 분기 처리 흐름으로만 된 로직을 에이전트화를 시켜보려고 했습니다. 사용자 Query 가 들어오면? LLM 은 주식질문인지 아닌지 판단 후에, 일상질문이라면 하이퍼크로버 X를 거쳐서 답변을 하게 되고, 아니라면 그래프 흐름대로 여러 데이터 파이프라인을 거쳐 주식 매수가 를 알려주는 로직을 수행하게 됩니다. 스터디의 좋은 점은 일단 같은 스터디원끼리 공유하면서 공부를 하게 된다는 점인데요 크게 Agent 에는 관심이 없었는데 저는 그저 멀티모달 무새였으나, 에이전트를 고도화시키는 부분에서 React Agent를 연구하시는 신정열 님의 코드를 보게 되었고, 캬! 이게 Clean Code 지 싶어서 아 이거 리팩토링 정리해야겠다. 생각을 하였습니다. 아마 저희가 만든 코드들이 다음 달이나 시연회나, 발표를 하지 않을까 싶습니다.
코드를 읽어보는데 직관적으로 되어 너무 좋았습니다. 사실 조금 이해 안 되는 부분도 있지만, 랭그래프 관련 딥한 부분이라 결과적으로 tool을 모아두고 toolkit의 형태로 선언을 해두면, 그 툴킷을 에이전트가 골라서 쓰게끔 만들면 되겠다.
이전에 그냥 WebSearchTool과 같은 툴을 가져다만 썼고, 커스터마이징을 해야 하는 상황이었습니다.
#설명
import yfinance as yf
from typing import Dict, Any, Optional
from datetime import datetime
import asyncio
from langchain_core.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
from langchain_core.callbacks import (
AsyncCallbackManagerForToolRun,
CallbackManagerForToolRun,
)
class CompanyDataInput(BaseModel):
symbol: str = Field(description="회사의 주식 심볼 (예: 'AAPL')")
company_name: Optional[str] = Field(
default="", # 기본값 설정
description="회사명 (예: 'Apple')"
)
class CompanyDataTool(BaseTool):
name: str = "company_data"
description: str = "회사의 주가(시가, 종가, 고가, 저가, 거래량), 기본 정보, 재무 지표 등을 조회합니다."
args_schema: Type[BaseModel] = CompanyDataInput
return_direct: bool = False
def _run(
self,
symbol: str,
company_name: Optional[str] = "",
run_manager: Optional[CallbackManagerForToolRun] = None,
) -> Dict[str, Any]:
"""동기 실행을 위한 메서드"""
try:
ticker = yf.Ticker(symbol)
info = ticker.info
hist = ticker.history(period="1d")
if hist.empty:
return {"error": "주가 데이터를 가져올 수 없습니다."}
current_price = float(hist['Close'].iloc[-1])
open_price = float(hist['Open'].iloc[-1])
return {
"basic_info": {
"symbol": symbol,
"company_name": company_name,
"sector": info.get('sector', 'N/A'),
"industry": info.get('industry', 'N/A'),
"market_cap": info.get('marketCap', 'N/A'),
},
"stock_data": {
"current_price": current_price,
"open": open_price,
"high": float(hist['High'].iloc[-1]),
"low": float(hist['Low'].iloc[-1]),
"volume": int(hist['Volume'].iloc[-1]),
"day_change": float(((current_price - open_price) / open_price) * 100),
"timestamp": datetime.now().isoformat()
},
"financial_metrics": {
"pe_ratio": info.get('trailingPE', 'N/A'),
"dividend_yield": info.get('dividendYield', 'N/A'),
"beta": info.get('beta', 'N/A'),
"eps": info.get('trailingEps', 'N/A'),
}
}
except Exception as e:
return {"error": f"데이터 조회 중 오류 발생: {str(e)}"}
async def _arun(
self,
symbol: str,
company_name: str,
run_manager: Optional[AsyncCallbackManagerForToolRun] = None,
) -> Dict[str, Any]:
"""비동기 실행을 위한 메서드"""
# 비동기 컨텍스트에서 동기 메서드 실행
return await asyncio.get_event_loop().run_in_executor(
None, self._run, symbol, company_name, run_manager
)
기존에 LangChain OutputParser를 사용해 pydantic으로 하위 Task 인 심벌과 회사명을 추출하는 로직을 개발했다면 이 툴은 그대로 사용하되 주석에 잘 표시를 해주면 AI 가 스키마에 맞는 값을 잘 추출하고, 비동기 실행이 되는 로직입니다. 위 코드에서는 야후 파이낸스 데이터를 통해서 'AAPL' 애플 주식을 예로, 기본 정보값을 호출해 오는 Tool입니다. 사실 이건 뭐크게 차이는 없다고도 할 수 있지만, LLM 이 알아서 판단해서 결과까지 호출하는 로직으로 호출이 한번 줄어들었다 생각할 수 있습니다. 이건 사용자마다 다르겠지만 기존 로직이 안정성에서는 더 좋을 순 있으나 Agent는 알아서 판단을 하고 다시 호출하고, LLM 이 스스로 판단을 하게끔 해주기 때문에 더 에이전트에 가깝지 않나 생각합니다. 그렇게 약 5개의 기능을 3개의 Tool로 좁혔습니다.
class StockAnalysisGraph:
def __init__(self, bedrock_client):
self.llm = bedrock_client.llm
self.toolkit = [CompanyDataTool(), MarketDataTool(), TechnicalAnalysisTool()]
self.app = self._build_graph()
그래프 구현에서의 클래스 모듈화를 통해서 toolkit으로 들어가게 되고, 상태정의한 그래프는 app으로, LLM 은 Nova Pro를 활용하는 클래스로 구현을 하였습니다.
def _build_graph(self):
# 3. 프롬프트 템플릿 설정
system_prompt = """주식 시장 분석 도우미입니다.
다음 도구들을 사용하여 질문에 답변해야 합니다.
1. company_data - 회사의 기본 정보와 실시간 주가를 조회합니다
- 오직 나스닥 기업 개요, 재무정보, 현재 주가 등을 확인할 수 있습니다
2. market_data - 주요 시장 지수 데이터를 조회합니다
- 오직 나스닥 주요 지수의 현재가와 등락률을 확인할 수 있습니다
3. technical_analysis - 주식의 기술적 분석 지표를 계산합니다
- 주식의 이동평균선, RSI, MACD 등 다양한 기술적 지표를 분석할 수 있습니다
제공된 도구들의 기능 범위를 벗어나는 질문의 경우, 답변이 어렵다는 점을 알려드리겠습니다."""
tool_calling_prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder("chat_history", optional=True),
("human", "{input}"),
MessagesPlaceholder("agent_scratchpad"),
])
# 4. 도구 호출 에이전트 생성
tool_runnable = create_tool_calling_agent(self.llm, self.toolkit, prompt=tool_calling_prompt)
# 5. 상태 정의
class AgentState(TypedDict):
input: str
chat_history: List[str]
agent_outcome: Union[AgentAction, List, AgentFinish, None]
intermediate_steps: Annotated[List[tuple[AgentAction, str]], operator.add]
# 6. 노드 함수 정의
def run_tool_agent(state):
agent_outcome = tool_runnable.invoke(state)
return {"agent_outcome": agent_outcome}
tool_executor = ToolExecutor(self.toolkit)
def execute_tools(state):
agent_action = state["agent_outcome"]
steps = []
if not isinstance(agent_action, list):
agent_action = [agent_action]
for action in agent_action:
output = tool_executor.invoke(action)
steps.append((action, str(output)))
return {"intermediate_steps": steps}
# 7. 엣지 로직
def should_continue(data):
if isinstance(data["agent_outcome"], AgentFinish):
return "END"
return "CONTINUE"
# 8. 그래프 구성
workflow = StateGraph(AgentState)
workflow.add_node("agent", run_tool_agent)
workflow.add_node("action", execute_tools)
workflow.set_entry_point("agent")
workflow.add_edge("action", "agent")
workflow.add_conditional_edges(
"agent",
should_continue,
{
"CONTINUE": "action",
"END": END
}
)
# 9. 그래프 컴파일
return workflow.compile()
def run(self, query: str, chat_history: List[str] = None):
if chat_history is None:
chat_history = []
inputs = {
"input": query,
"chat_history": chat_history
}
return self.app.invoke(inputs)
def stream(self, query: str, chat_history: List[str] = None):
if chat_history is None:
chat_history = []
inputs = {
"input": query,
"chat_history": chat_history
}
return self.app.stream(inputs)
3개의 툴에 대해 설명해 주는 Prompt를 넣어서 도구들을 명확히 해서 호출할 수 있도록 해줍니다. 그래프의 흐름을 설명하면 agent 노드에서는 사용자의 질문을 분석하고 적절한 도구를 선택하는 단계이고, Action 노드에서는 그 도구를 실행해서 값을 가져옵니다. 만약 잘 가져왔다면 End로 종료가 될 것이고, 잘 안 가져왔다면 Agent로 다시 돌아가 도구를 다시 선택하는 로직입니다.
사용자: "애플의 현재 주가와 RSI 지표를 알려줘"
1. [agent] → 주가 확인 필요 → CONTINUE
2. [action] → 주가 조회 실행
3. [agent] → RSI 확인 필요 → CONTINUE
4. [action] → RSI 계산 실행
5. [agent] → 모든 정보 수집 완료 → END
기존의 20초 이상 걸리던 흐름이 지금은 많이 개선되었습니다. 비동기 처리로 최대한 로직을 동시처리하도록 하였고, 이제 3개의 툴을 합쳐서 주가정보를 예측할 때용으로 쓰는 tool을 하나 더 만들어서 작동시킬 예정입니다.

재밌는 것은 Nova 기반의 모델이란 건데, 다른 프런티어 모델 못지않게 잘 답변해 주는 것이 특징입니다. 더 써봐야 알겠지만 가격적으로 너무 메리트가 있어서, 당분간 Nova에 정착하지 않을까 싶습니다. 추후 Tool 들의 기능을 더 고도화 업데이트 해서 좋은 프로젝트 산출물로 돌아오겠습니다.
'NLP' 카테고리의 다른 글
| [Agent Study] 에이전트를 활용하여 멀티 DB 연결 구축하기 (0) | 2024.12.20 |
|---|---|
| [Agent Study] Multi-Agent , Multi-tool 만들기 - (1) : Custom Tool 만들기 (0) | 2024.12.18 |
| LangChain 으로 HyperClovaX 적용하는 방법 (1) | 2024.10.30 |
| CrewAI 로 LLM Agent 푹 담궈 찍어먹어보기 (0) | 2024.09.04 |
| 실전 데이터를 활용한 LLM Fine-tunning, RAG 적용해보기 (EXAONE Finetuning) - (1) (3) | 2024.08.22 |



