안녕하세요 Simon 입니다.
이번 포스팅할 게시물은 차기 Transformers 기반의 AI 생태계를 변화시킬 수 있을지 집중이 되고있는 MoE에 대해서 알아보겠습니다.
모든 게시물은 Hugging Face 에 소개된 게시물을 토대로 작성되었습니다.
https://huggingface.co/blog/moe#what-is-a-mixture-of-experts-moe
Mixture of Experts Explained
Mixture of Experts Explained With the release of Mixtral 8x7B (announcement, model card), a class of transformer has become the hottest topic in the open AI community: Mixture of Experts, or MoEs for short. In this blog post, we take a look at the building
huggingface.co
요즘 대세가 적은 파라미터로, 효율적인 추론을 하는것이다. 아무래도 파라미터가 많을 수록 리소스 부담이 있기 때문이기도하고, 프롬프트 엔지니어링 RAG 와 같은 방법론 덕분에 더 효율적인 LLM 서비스 구축 방법들이 계속 나오고 있기 때문이다.

What is MoE?
모델의 규모는 모델 품질 향상을 위한 가장 중요한 축 중 하나입니다. 컴퓨팅 예산이 고정되어 있다면 더 적은 단계로 더 큰 모델을 훈련하는 것이 더 많은 단계로 더 작은 모델을 훈련하는 것보다 낫습니다. 전문가 혼합을 사용하면 훨씬 적은 컴퓨팅으로 모델을 사전 학습할 수 있으므로 고밀도 모델과 동일한 컴퓨팅 예산으로 모델 또는 데이터 세트 크기를 크게 확장할 수 있습니다. 특히 MoE 모델은 사전 학습 중에 고밀도 모델과 동일한 품질을 훨씬 빠르게 달성해야 합니다.
- 효율적인 사전 학습: MoE는 더 효율적인 사전 학습을 가능하게 하지만, 미세 조정 시 일반화에 어려움을 겪을 수 있으며 과적합이 발생할 수 있습니다.
- 빠른 추론: MoE는 많은 파라미터를 가지고 있지만, 추론 시 일부만 사용되어 밀집 모델에 비해 추론 속도가 빠릅니다. 하지만 모든 파라미터를 RAM에 로드해야 하므로 메모리 요구 사항이 높습니다. 예를 들어, Mixtral 8x7B와 같은 MoE 모델은 47B 파라미터 모델을 VRAM에 로드해야 합니다. 이는 MoE 모델에서 FFN 레이어만 각각의 전문가로 취급되고 나머지 모델 파라미터는 공유되기 때문입니다. 한편, 토큰당 두 개의 전문가만 사용한다고 가정하면, 추론 속도(FLOPs)는 12B 모델과 비슷합니다(14B 모델이 아니라), 왜냐하면 2x7B 행렬 곱셈을 계산하지만 일부 레이어가 공유되기 때문입니다.

스위치 트랜스포머(Switch Transformer) 인코더 블록의 구조를 나타내고 있습니다. 여기서는 트랜스포머 모델의 밀집 피드포워드 네트워크(FFN) 레이어를 스파스 스위치 FFN 레이어(연한 파란색으로 표시됨)로 대체하고 있습니다. 이 레이어는 시퀀스 내의 토큰들에 독립적으로 작동합니다.
그림에서는 두 개의 토큰(x1 = "More"와 x2 = "Parameters")이 네 개의 FFN 전문가들에게 라우팅되는 것을 보여줍니다. 여기서 라우터는 각 토큰을 독립적으로 라우팅합니다. 스위치 FFN 레이어는 선택된 FFN의 출력을 라우터 게이트 값과 곱한 결과를 반환합니다(점선으로 표시됨).
기존 트랜스포머랑 무슨 차이인가?
- 레이어 구조: 기존 트랜스포머 모델은 밀집 피드포워드 네트워크(FFN) 레이어를 사용합니다. 이는 각 레이어에서 모든 뉴런이 활성화되어 모든 입력에 대해 연산을 수행합니다. 반면, MoE 모델에서는 밀집 FFN 레이어가 스파스 FFN 레이어로 대체됩니다. 이 스파스 레이어는 '전문가'라고 불리는 여러 작은 네트워크로 구성되며, 각 입력 토큰은 가장 관련성이 높은 '전문가'에 의해서만 처리됩니다.
- 효율성: 기존 트랜스포머는 모든 입력에 대해 모든 파라미터를 사용합니다. MoE 모델은 토큰마다 다른 '전문가'가 활성화되기 때문에, 특정 입력에 대해 활성화되는 파라미터의 수가 적어집니다. 이는 계산 효율성을 크게 향상시키며, 주어진 컴퓨팅 리소스로 더 큰 모델을 학습할 수 있게 합니다.
- 라우팅 메커니즘: MoE 모델은 각 토큰을 어느 '전문가'에게 전송할지 결정하는 라우팅 메커니즘을 포함합니다. 이는 기존 트랜스포머에서 볼 수 없는 특징으로, 모델의 효율성과 성능을 최적화하는 데 중요한 역할을 합니다.
- 메모리 요구 사항: 기존 트랜스포머 모델은 모든 파라미터를 항상 메모리에 로드해야 합니다. MoE 모델은 추론 시 일부 파라미터만 사용하지만, 전체 파라미터 세트를 메모리에 유지해야 하는 높은 메모리 요구 사항이 있습니다.
- 학습 및 미세 조정의 복잡성: MoE 모델은 학습 시 더 복잡한 최적화 과정을 거칠 수 있으며, 특히 미세 조정 단계에서 일반화 문제에 직면할 수 있습니다.
기존 트랜스포머와 MoE 모델의 주요 차이점은 MoE가 효율적인 계산을 위해 입력에 대해 선택적으로 활성화되는 여러 '전문가' 네트워크를 사용한다는 것입니다.

조금 개념이 어려워서 GPT에게 물어보니 맞다고 하네요 ㅎㅎ;
모델의 이점과 도전 과제
- 효율적인 사전 학습: MoE는 전통적인 밀집 모델보다 훨씬 효율적인 사전 학습을 가능하게 합니다. 이는 모델이 더 크고 복잡한 데이터 세트를 더 빠르게 학습할 수 있게 만듭니다.
- 학습 중의 도전 과제: MoE 모델은 사전 학습에서는 효율적이지만, 미세 조정 단계에서 일반화에 어려움을 겪을 수 있으며, 이는 과적합으로 이어질 수 있습니다.
- 추론 속도: MoE 모델은 많은 파라미터를 가지고 있지만, 추론 과정에서는 일부 파라미터만 사용됩니다. 이는 동일한 수의 파라미터를 가진 밀집 모델에 비해 추론 속도를 크게 향상시킵니다. 그러나 모든 파라미터가 RAM에 로드되어야 하므로 높은 메모리 요구 사항이 있습니다.
예를 들어, Mixtral 8x7B와 같은 MoE 모델의 경우, 47B 파라미터의 밀집 모델을 VRAM에 로드할 수 있어야 합니다. 왜 56B(8 x 7B)가 아니냐면, MoE 모델에서는 FFN 레이어만 각각의 전문가로 취급되고, 나머지 모델 파라미터는 공유되기 때문입니다. 동시에 토큰당 두 개의 전문가만 사용한다고 가정할 때, 추론 속도(FLOPs)는 2x7B 행렬 곱셈을 수행하지만 일부 레이어가 공유되므로 14B 모델이 아닌 12B 모델과 유사합니다.
-> inference 과정에서 추론할때 RAM 사용량은 기존의 모델보다 많다고 한다. 예를 들어, Mixtral 8x7B와 같은 MoE 모델의 경우, 전체 모델 파라미터 중 FFN 레이어만 각각의 전문가로 취급되고, 나머지 파라미터는 공유됩니다. 이는 전체 파라미터 중 상당 부분이 RAM에 상주해야 함을 의미합니다.
A Brief History of MoEs
기원 (1991년): MoE의 뿌리는 1991년의 논문 "Adaptive Mixture of Local Experts"에 있습니다. 이 아이디어는 앙상블 방법과 유사하게, 각기 다른 훈련 사례들을 처리하는 별도의 네트워크로 구성된 시스템에 대한 감독된 절차를 가지는 것이었습니다. 각각의 별도 네트워크, 또는 전문가는 입력 공간의 다른 영역을 전문으로 합니다. 전문가는 어떻게 선택되나요? 게이팅 네트워크가 각 전문가에 대한 가중치를 결정합니다. 훈련하는 동안 전문가와 게이팅 모두 훈련됩니다.
2010-2015년 사이의 연구: 이 시기에 두 가지 다른 연구 분야가 나중의 MoE 발전에 기여했습니다.
- 전문가들이 구성 요소로서의 역할: 전통적인 MoE 설정에서 전체 시스템은 게이팅 네트워크와 여러 전문가로 구성됩니다. SVM, Gaussian Processes 등에서 MoE가 전체 모델로 탐구되었습니다. Eigen, Ranzato, 그리고 Ilya의 연구는 더 깊은 네트워크의 구성 요소로서 MoE를 탐구했습니다. 이를 통해 다층 네트워크에서 MoE 레이어를 사용할 수 있게 되어 모델이 크면서도 동시에 효율적일 수 있게 되었습니다.
- 조건부계산: 전통적인 네트워크는 모든 입력 데이터를 모든 레이어를 통해 처리합니다. 이 기간 동안 Yoshua Bengio는 입력 토큰에 따라 구성 요소를 동적으로 활성화하거나 비활성화하는 접근 방법을 연구했습니다.

게이팅 네트워크(Gating Network): 이는 입력 G(x)에 대한 가중치를 계산하여 각 전문가가 처리할 토큰을 결정합니다. 이 네트워크는 입력 G(x)를 받아 각 전문가에 대한 가중치를 출력하고, 이 가중치는 해당 전문가가 처리할 입력 토큰의 중요성을 나타냅니다.
전문가(Experts): 이들은 독립적인 신경망으로, 각기 다른 유형의 입력 데이터를 전문으로 처리합니다. 여기서는 n개의 전문가가 있으며, 각각은 서로 다른 기능을 수행할 수 있습니다.
MoE layer 구조:
- 입력 G(x)는 먼저 게이팅 네트워크를 통해 전달됩니다.
- 게이팅 네트워크는 각 전문가에 대한 가중치를 결정합니다.
- 이 가중치에 따라 입력은 여러 전문가 중 하나 또는 여러 개에 할당됩니다.
- 각 전문가는 할당된 입력 부분에 대해 연산을 수행합니다.
- 그런 다음 각 전문가의 출력은 게이팅 네트워크에서 결정된 가중치와 곱해집니다.
- 모든 전문가의 가중치가 적용된 출력은 합산되어 MoE 레이어의 최종 출력을 형성합니다.
What is Sparsity?

- Shazeer의 연구는 번역을 위한 MoE의 사용을 더 깊이 탐구하면서 조건부 계산을 통해 수천 명의 전문가를 각 MoE 레이어에 통합하는 방법을 제시했습니다. 그러나 이러한 접근 방식은 데이터가 다양한 전문가들을 통과하면서 실제 배치 크기가 감소하는 등의 새로운 도전과제를 만들어냈습니다.
- 이러한 도전과제에 대응하기 위해, 학습된 게이팅 네트워크는 각 입력의 일부를 어느 전문가에게 보낼지 결정합니다. 이는 가중치가 적용된 합계를 통해 계산되며, 특정 게이팅 값이 0이 되면 해당 전문가에 대한 계산이 생략되어 계산 효율성이 더욱 향상됩니다.
- Shazeer의 연구는 노이지 탑-k 게이팅과 같은 게이팅 메커니즘을 탐구하여, 노이즈를 추가하고 상위 k 전문가만을 선택하는 방법으로 희소성을 도입했습니다. 이러한 희소성은 모델을 훨씬 빠르게 훈련시키고 추론을 수행할 수 있도록 하면서도, 모델이 다양한 전문가에게 입력을 분배하며 학습하는 방법을 배울 수 있게 합니다. 노이즈를 추가하는 이유는 로드 밸런싱과 관련이 있어, 모든 전문가가 고르게 활용될 수 있도록 합니다.
Load balancing tokens for MoEs
만약 모든 입력 토큰이 몇몇 인기 있는 전문가들에게만 전송된다면, 이는 훈련을 비효율적으로 만들 것입니다. 일반적인 MoE 훈련에서 게이팅 네트워크는 동일한 몇몇 전문가들을 주로 활성화하도록 수렴하는 경향이 있습니다. 이는 선호되는 전문가들이 더 빨리 훈련되고, 결과적으로 더 자주 선택되는 자기강화 피드백 루프를 만들어냅니다. 이를 완화하기 위해, 모든 전문가들이 균등한 중요도를 갖도록 장려하는 보조 손실(auxiliary loss)이 추가됩니다. 이 손실은 모든 전문가들이 대략적으로 동일한 수의 훈련 예시를 받도록 보장합니다.
- 이는 각 전문가가 처리할 수 있는 토큰의 수에 대한 임계값을 도입하는 개념입니다. 트랜스포머 모델에서는 이 보조 손실이 aux_loss 매개변수를 통해 적용됩니다
MoEs and Transformers
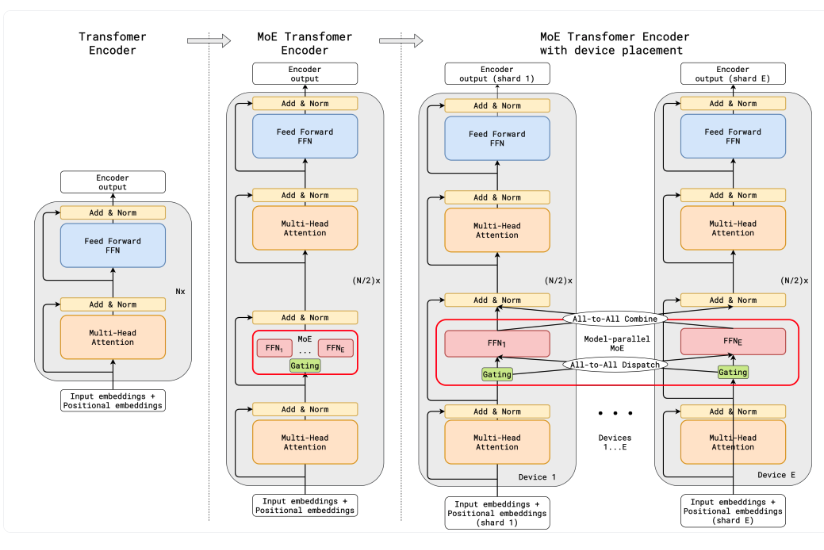
GShard라는 구글의 연구로, MoE(전문가 혼합) 레이어를 사용하여 트랜스포머 모델을 6000억 개 이상의 파라미터로 확장하는 방법을 탐구합니다. 파라미터 수를 늘리면 성능이 향상되는 것은 잘 알려진 사실이며, GShard는 이를 실현하기 위해 각 인코더와 디코더의 FFN 레이어 중 일부를 MoE 레이어로 대체합니다.
랜덤 라우팅: top-2 설정에서 우리는 항상 최고의 전문가를 선택하지만, 두 번째 전문가는 그 가중치에 비례하는 확률로 선택됩니다.전문가 용량: 한 전문가가 처리할 수 있는 토큰의 수에 대한 임계값을 설정할 수 있습니다. 만약 두 전문가 모두 용량이 가득 차 있다면, 토큰은 오버플로우된 것으로 간주되어 잔여 연결을 통해 다음 레이어로 전송되거나(또는 다른 프로젝트에서는 완전히 삭제됩니다). 전문가 용량이라는 개념은 MoE에 있어 가장 중요한 개념 중 하나가 될 것입니다. 전문가 용량이 필요한 이유는 모든 텐서 형태가 컴파일 시점에 정적으로 결정되지만, 얼마나 많은 토큰이 각 전문가에게 갈지 미리 알 수 없기 때문에 용량 인자를 고정해야 합니다.
Transformer 와 MoE Transformer 의 차이?
- 레이어 구조: MoE 트랜스포머는 일부 피드포워드 네트워크(FFN) 레이어를 MoE 레이어로 대체합니다. 이 MoE 레이어는 여러 '전문가' 네트워크를 포함하고, 이들 각각은 입력 데이터의 서로 다른 부분을 전문적으로 처리합니다.
- 게이팅 메커니즘: 게이팅 네트워크는 각 입력 토큰을 어느 전문가에게 보낼지 결정합니다. 일반적으로 상위 k개의 전문가를 선택하는 'Top-k 게이팅' 방식이 사용되며, 이는 모델의 효율성과 성능을 향상시킵니다.
- 조건부 계산: MoE 모델에서는 모든 입력에 대해 모든 파라미터를 사용하지 않고, 필요한 부분에 대해서만 파라미터를 활용합니다. 이것은 조건부 계산이라고 불리며, 모델의 계산 효율성을 향상시킵니다.
- 스케일링과 효율성: MoE 트랜스포머는 대규모 파라미터를 보다 효율적으로 관리하고, 특히 대규모 컴퓨팅 환경에서 모델을 확장하는 데 유리합니다. 각 장치에 모델의 일부를 분산시켜 로드를 분배하고 전문가 레이어를 장치 간에 공유할 수 있습니다.
- 로드 밸런싱: MoE 트랜스포머는 로드 밸런싱을 통해 모든 전문가가 균등하게 활용되도록 합니다. 이를 위해 랜덤 라우팅, 전문가 용량 제한 등의 메커니즘을 도입하여 전문가가 과부하되는 것을 방지합니다.
- 훈련과 추론의 차이: MoE 모델은 추론 시에만 일부 전문가가 활성화되는 반면, 기존 트랜스포머는 모든 입력에 대해 모든 파라미터를 활용합니다. 이는 MoE 모델이 추론 시 더 빠르고 효율적일 수 있음을 의미합니다.
Feeling
AI 기술의 끊임없는 발전은 항상 새로운 변곡점에 서 있고, 최근 이 분야에서 가장 주목 받고 있는 변화 중 하나는 MoE(Mixture of Experts) 트랜스포머의 등장입니다. Hugging Face의 글을 통해 MoE에 대해 깊이 있게 알아본 결과, 이 새로운 접근 방식이 기존의 트랜스포머 모델을 어떻게 능가할 수 있는지 명확히 이해할 수 있었습니다. MoE 모델은 계산 효율성을 크게 향상시키는 동시에, 모델 사이즈를 기하급수적으로 확장할 수 있는 가능성을 제시합니다. 이는 고정된 컴퓨팅 리소스를 가지고도 더 빠르고 효율적으로 대규모 모델을 학습시킬 수 있음을 의미합니다. 특히 Mixtral 8x7B와 같은 MoE 모델은 기존 모델과 비교했을 때 추론 속도의 현저한 개선을 제시하면서도, 그만큼의 높은 메모리 요구 사항을 가져올 수 있다는 점에서 새로운 도전을 안고 있습니다. MoE의 역사적 맥락을 살펴보고, 1991년부터 시작된 이 아이디어가 어떻게 지난 수십 년 간 진화해 왔는지 이해함으로써, 현재 AI 분야에서 MoE가 갖는 중요성을 더욱 깊이 인식하게 되었습니다. 2010년부터 2015년 사이의 연구는 더 깊은 네트워크의 구성 요소로서 MoE를 탐구하며, 조건부 계산과 같은 새로운 개념을 도입해 높은 효율성을 달성하였습니다. 게이팅 네트워크와 각각의 독립적인 전문가들이 복잡한 입력 데이터를 어떻게 처리하는지를 파악함으로써, MoE 모델이 일반화와 과적합이라는 두 가지 주요 도전 과제에 어떻게 접근하고 있는지에 대한 이해가 깊어졌습니다. 또한, GShard의 연구는 MoE 모델이 수천 억 개의 파라미터를 활용하여 어떻게 대규모로 확장될 수 있는지 보여주며, 전문가 용량 및 랜덤 라우팅과 같은 기법을 통해 로드 밸런싱 문제를 해결하는 방법을 제시합니다. 이 모든 지식을 바탕으로 MoE 모델이 향후 AI 생태계를 어떻게 변화시킬지에 대해 고찰해보았습니다. 고정된 파라미터 세트를 넘어서 모델의 유연성과 성능을 높이는 새로운 시대가 열리고 있음을 목격하는 것은 매우 흥미롭습니다. MoE는 단순히 새로운 모델 구조를 넘어서 AI의 미래를 재정의하는 중요한 요소가 될 것으로 보입니다. MoE의 장점을 최대한 활용하면서 동시에 그 한계를 극복하는 방법을 찾는 것이, 우리가 나아가야 할 방향임에 틀림없습니다.



