오늘 소개해드릴 논문은 LLM2 LLM입니다. 이름에서도 직관적으로 LLM을 통하여 새로운 데이터를 사용해서 LLM을 강화한다인데 이전에 강화학습 방법인 knowledge distillation과 연관이 있는지 한번 확인해 봐야겠습니다.(일반적으로 knowledge distillation 은 강화학습 방법으로 유명한데요 sLLM을 거대한 LLM 이 선생님이 되어 지식을 주입하는 방법론이라고 할 수 있습니다.) Distilling the Knowledge in a Neural Network라는 논문에서 등장한 개념으로 나중에 리뷰해 보겠습니다.
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
Pretrained large language models (LLMs) are currently state-of-the-art for solving the vast majority of natural language processing tasks. While many real-world applications still require fine-tuning to reach satisfactory levels of performance, many of the
arxiv.org
GitHub - SqueezeAILab/LLM2LLM: LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement
LLM2LLM: Boosting LLMs with Novel Iterative Data Enhancement - SqueezeAILab/LLM2LLM
github.com
Abstract
사전 훈련된 대규모 언어 모델(LLMs)이 다양한 자연어 처리(NLP) 작업에서 최고의 기술 상태(state-of-the-art) 임을 언급하며 시작합니다. 이러한 모델들은 대부분의 실제 애플리케이션에서 만족스러운 성능 수준에 도달하기 위해 미세 조정이 필요하지만, 데이터가 부족한 상황에서는 이러한 미세 조정이 어려울 수 있습니다. 이 문제를 해결하기 위해, 연구팀은 LLM2 LLM이라는 타겟팅 및 반복적 데이터 증강 전략을 제안합니다. 이 전략은 선생 LLM을 사용하여 특정 작업에 대해 미세 조정할 수 있는 추가 데이터로 작은 초기 데이터 세트를 강화합니다.
LLM2 LLM 접근 방식 3단계:
1. 초기 시드 데이터에 대한 기준 학생 LLM의 미세 조정.
2. 모델이 잘못 예측한 데이터 포인트의 평가 및 추출.
3. 잘못된 데이터 포인트를 기반으로 한 교사 LLM에 의한 합성 데이터 생성, 이 데이터는 훈련 데이터에 다시 추가됩니다.

이 방법은 LLM이 훈련 중에 잘못 예측한 데이터 포인트에서 신호를 증폭하고, 이를 데이터 세트에 재통합하여 LLM에 대한 더 도전적인 예시에 초점을 맞춥니다. 연구 결과는 LLM2 LLM이 전통적인 미세 조정 및 다른 데이터 증강 기준보다 우수한 성능을 보여주며, 데이터 부족 환경에서 LLM의 성능을 크게 향상한다는 것을 보여줍니다. 특히, GSM8 K, CaseHOLD, SNIPS, TREC, SST-2 데이터 세트에서 상당한 성능 향상을 달성했으며, 이는 데이터 수집에 소요되는 노력을 줄이고, 데이터 제약이 있는 도메인 및 작업을 다룰 수 있는 더 확장 가능하고 성능이 우수한 LLM 설루션으로 나아갈 수 있는 가능성을 열어줍니다. LLaMA2-7B Student Model을 사용하여 데이터가 부족한 환경에서의 정규 미세 조정보다 최대 24.2%에서 52.6%까지의 성능 개선을 보고합니다
모든 LLM 관련한 게 똑같겠지만 결국 Data 가 중요할 것 같다. Teach model에서 올바로 바로잡고 간다고 해도 Teacher 모델에 잘못된 정보가 있거나 할루시네이션이라면 결국은 똑같이 의미 없는 학습이 되지 않을까 생각을 했다. 그런 점 까진 물론 생각을 한 것은 아니겠지만 아키텍처는 결국 seed data에서 튜닝을 하고 Wrong examples을 추출해서 티처모델에게 다시 전달해서 데이터를 학습시키고 그 데이터를 다시 파인튜닝 하는 방식이다. 그렇다면 기존의 데이터 한정해서는 할루시네이션을 잡아줄 방법의 대안이 될 수도 있겠다 생각이 들었다.
1 Introduce
사전 훈련된 대규모 언어 모델(LLMs)이 다양한 벤치마크와 데이터셋에서 인상적인 성과를 거두었지만, 실제 세계의 다양한 응용 프로그램에서는 여러 도전 과제에 직면해 있다는 것을 설명합니다. LLM들은 입력 문맥을 처리하는 데 한계가 있으며, 특히 전문 분야나 특정 의학 분야와 같이 특화된 도메인에서는 적절한 성능을 달성하기 위해 긴 프롬프트가 필요할 수 있습니다. 이는 추론의 지연 시간과 비용을 증가시킬 뿐만 아니라, LLM이 긴 문맥 정보를 잊거나 무시할 수 있어 정확도가 떨어질 수 있습니다. 이러한 문제에 대한 해결책으로 미세 조정이 제안되었습니다. 특히, 효율적인 미세 조정 방법(PEFT)의 등장으로 작업 특정 LLM을 미세 조정하는 데 필요한 계산 자원이 크게 감소했습니다. 그러나 성공적인 미세 조정을 위해서는 충분한 훈련 데이터가 필요한데, 이는 일부 애플리케이션에서 큰 도전 과제가 될 수 있습니다. 데이터 증강은 훈련 데이터셋을 확장하는 데 도움이 될 수 있는 알려진 방법이지만, 새롭고 특수한 작업에 대해 LLM을 미세 조정하는 경우에는 이러한 전통적인 방법들이 효과적이지 않을 수 있습니다. 이러한 배경을 바탕으로, 연구팀은 LLM2 LLM이라는 새로운 타기팅 및 반복적 데이터 증강 프레임워크를 소개합니다. 이 기술은 선생님 LLM을 사용하여 학생 LLM이 초기 데이터셋에 대해 미세 조정된 후 잘못된 데이터 포인트를 평가하고 추출하여, Self-Instruct 스타일의 데이터 증강으로 이를 증강하고 훈련 데이터에 다시 추가하는 방식으로 작업 특정 데이터셋을 효율적이고 효과적으로 증강합니다. LLM2 LLM의 효과는 GSM8 K, CaseHOLD, SNIPS, TREC, SST-2 데이터셋에서의 성능 향상을 통해 입증되었으며, 연구팀은 이 기술의 설계 결정의 효과성을 평가하기 위해 여러 기존 베이스라인 및 LLM2 LLM 변형과의 비교 연구를 수행하였습니다. 연구 결과는 LLM2 LLM의 반복적이고 타기팅 된 특성이 모델 성능 향상에 결정적으로 중요함을 보여줍니다.
2 Background and Related Work
2.1 Instruction Following LLMs
최초의 지시 사항을 따르는 미세 조정 연구는 다양한 NLP 데이터셋을 수집하고 처리하여 LLMs의 다양한 작업에 대한 성능을 개선하는 데 초점을 맞췄습니다. Self-Instruct는 모델 자체의 출력을 이용하여 지시 데이터셋을 부트스트래핑 하는 프레임워크를 도입함으로써 기존 데이터셋에 대한 의존도를 제거했습니다. 이후의 작업은 더 강력한 일반 목적의 지시 사항을 따르는 모델을 미세 조정하기 위해 강력한 모델을 활용했습니다.
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Large "instruction-tuned" language models (i.e., finetuned to respond to instructions) have demonstrated a remarkable ability to generalize zero-shot to new tasks. Nevertheless, they depend heavily on human-written instruction data that is often limited in
arxiv.org
위 논문을 읽어보면 좋을 듯하다. instruction 튜닝한 데이터를 Large Scale Langauage model로 학습을 해도 성능이 개선된다는 논문이다. LLM의 의존도가 높을 수 있다 (LM이 커야 함)
2.2 Self-Improving LLMs
Self-Improving을 사용하여 LLMs를 미세 조정하는 다양한 초기 연구가 있습니다. 이러한 연구는 일반적으로 모델의 출력을 미세 조정하기 전에 필터링했습니다. LLM2 LLM은 이러한 방법과 다르며, 우리는 자체 모델의 출력에 직접 미세 조정하지 않고 합성 데이터 형태로 피드백을 제공하는 교사 모델을 활용합니다. 동시에 진행된 여러 연구는 LLMs를 개선하기 위한 반복적 접근법을 사용했습니다. 이러한 작업은 강화 학습(RL)과 자가 대결(Self-Play)에서 영감을 받아 모델 자체의 출력에 미세 조정함으로써 반복적으로 더 강력한 LLMs를 구축하는 아이디어를 결합했습니다. LLM2 LLM은 특히 저 데이터 환경에서 작업 특정 LLM의 미세 조정에 초점을 맞추며, 다른 연구들은 일반 목적의 강력한 LLMs를 생성하려고 시도합니다. 위에 Abstrack에서 설명한 내용이다.
2.3 Data Augmentation
NLP에서 데이터 증강은 오랫동안 연구되어 왔습니다. 초기 연구는 문자 및 단어 수준에서 데이터를 증강했습니다. 특히, Easy Data Augmentation(EDA)은 동의어 교체, 무작위 삽입, 교환, 삭제 등 단어 수준의 증강을 사용하여 텍스트 분류를 위한 데이터를 증강하는 인기 있는 초기 방법이었습니다. NLP에서의 데이터 증강에 대한 보다 완전한 요약은 해당 참고 문헌에서 찾을 수 있습니다. 새롭고 인기 있는 접근 방법은 LLMs 자체를 사용하여 새로운 훈련 데이터를 합성하는 것입니다. 주목할 만한 예로는 텍스트 분류 작업을 증강하기 위해 ChatGPT를 사용하여 텍스트를 다시 표현한 AugGPT가 있습니다. 이러한 기술은 대량의 합성 데이터를 생성합니다. 최근 연구는 이러한 대규모 데이터셋에서 미세 조정의 결과를 상당히 작은 하위 집합으로 재현할 수 있음을 발견했습니다.
근데 결국 사람이 원하는 대로, model을 만들고 싶다면 사람이 개입되는 게 아주 아닐까.. 조심스럽게 생각도 든다. 아직은..
3 Methodology
LLM2 LLM 방법론은 사전 훈련된 대규모 언어 모델(LLM), 예를 들어 GPT-3.5 또는 LLaMA2-7B 같은 모델을 새로운 대상 도메인에 적응시키는 과정에 초점을 맞춥니다. 이 과정에서는 소규모의 시드 데이터셋 D를 사용하는데, 이 데이터셋은 사전 훈련 데이터셋과 비교하여 본 적 없는 특징을 가질 수 있습니다(예: 특정 용어를 사용하는 의료 데이터셋, 특정 특성을 가진 개인 데이터베이스 등). 이 경우, 모델의 제로샷 또는 미세 조정된 성능은 만족스럽지 않을 가능성이 높습니다.
LLM2 LLM은 대상 훈련 데이터셋의 모든 사용 가능한 데이터 포인트에 프롬프트 된 LLM을 적용하여 추가 증강 데이터를 생성하는 유망한 접근법인 AugGPT에 의해 소개된 방법을 확장합니다. 그러나 이 방법은 학생 모델의 다양한 데이터 포인트에 대한 성능을 고려하지 않고 데이터를 무차별적으로 증강하는 데 한계가 있습니다. 예를 들어, 모델이 데이터셋의 대부분을 쉽게 해결할 수 있지만, 더 도전적인 소수의 예시에 어려움을 겪을 수 있습니다. 이 경우, 단순한 사례를 복제하여 데이터셋을 무차별적으로 확장하는 것보다는 이 도전적인 예시와 개념적으로 일치하는 더 많은 데이터 포인트를 생성하는 것이 더 나은 증강 전략이 될 수 있습니다.
LLM2 LLM에서는 이러한 한계를 해결하기 위해 다음과 같은 반복 과정을 고려하는 보다 일반적인 LLM 기반 데이터 증강 파이프라인을 제안합니다:
알고리즘 자체는 그렇게 어렵지 않았다. 데이터를 생성하는 측면에서 , 리소스가 매우 적은 상황에서 유용하겠다 생각이 들었다. 여기서 저 Fiter단계가 매우 중요해 보이는데 어떻게 처리를 하냐? 가 많이 궁금해졌다.
3.1 LLM2 LLM
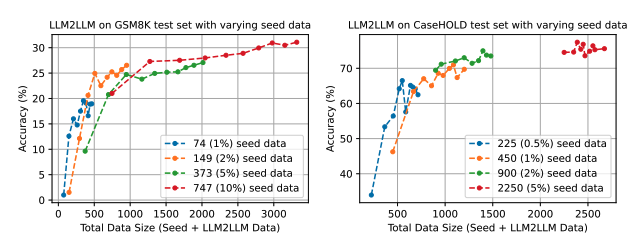
Data 가 증가 될수록 Accuracy 가 올라가는 것을 볼 수 있었다.

첫 번째 스탭에서 잘못된 데이터의 비율을 P라 할 때 계산되는 수식이다. 각 반복에서 생성된 증강 데이터를 포함해서 다음 반복의 시드 데이터로 사용할 때 데이터셋 크기가 지수적으로 증가한다는 뜻이다 Pmin 은 잘못된 데이터의 최솟값이다.
두 번째 스탭에서는 증강 데이터가 원래 시드 데이터로부터만 생성될 때 데이터셋의 크기가 단계마다 선형적으로 증가한다는 수식이다. Pmax는 잘못된 데이터의 최댓값이다.
결과적으로 데이터를 증강시킬 때 새롭게 생성된 데이터를 시드 데이터에 포함시키지 않는다면, 증강 데이터의 양을 통제하고, 데이터품질을 유지 관리 할 수 있다는 뜻이다.
4 Results
LLaMA2-7B와 같은 LLM을 GPT-3.5를 선생 모델로 사용하여 GSM8K에서 미세 조정하는 경우, 훈련 데이터의 양이 변할 때 LLM2 LLM의 성능을 논의하며 표 1에 결과를 설명하면서 결과에 대해 얘기한다.
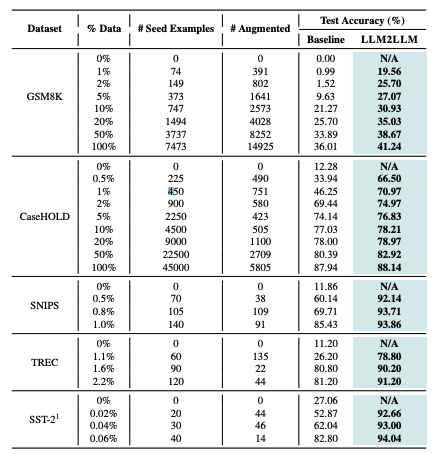
- 데이터가 적은 상황에서 기본 모델은 매우 낮은 테스트 정확도를 보입니다. 예를 들어, GSM8 K 훈련 데이터셋의 1%에 해당하는 74개의 예제만을 사용했을 때, 테스트 정확도는 0.99%입니다.
- LLM2 LLM은 모델이 오류를 범하는 지점을 기반으로 추가 예제를 생성함으로써 테스트 정확도를 크게 향상합니다. 같은 74개의 예제를 사용했을 때 LLM2 LLM은 정확도를 19.56%로 높입니다.
- 더 많은 데이터는 일반적으로 더 높은 정확도를 의미하지만, LLM2 LLM은 작은 양의 데이터에서도 상당한 향상을 보여줍니다. 예를 들어, 훈련 데이터셋의 2%를 사용했을 때 LLM2LLM은 25.70%의 정확도를 달성하는 반면, 기본 모델은 이와 같은 성능을 달성하기 위해 10배 이상의 데이터가 필요합니다.
- LLM2LLM은 데이터가 충분한 상황에서도 효과적이지만, 특히 데이터가 부족한 상황에서 성능 향상이 두드러집니다.
- CaseHOLD, SNIPS, TREC, SST-2와 같이 다양한 데이터셋에서도 LLM2 LLM은 특히 데이터가 적을 때 성능을 향상하는 데 도움이 됩니다.
- LLM2 LLM은 GSM8K와 같이 더 도전적인 데이터셋에서 비례적으로 더 많은 데이터를 생성하는 경향이 있습니다.
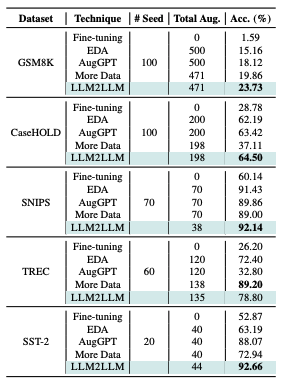
Iterative Augmentation vs One-Shot Augmentation : 여러 단계에 걸쳐 예제 당 하나의 데이터 포인트를 반복해서 증강하는 것이 한 번에 모든 증강 데이터를 추가하는 것보다 효과적임을 나타냅니다.

Data Augmentation with Seed Data vs Augmented Data : 오직 시드 데이터만 재증강하는 것이 잠재적인 데이터 품질 저하를 피하는 데 더 효과적임을 보여줍니다.
From-Scratch Fine-tuning vs Continuous Fine-tuning : 각 반복에서 처음부터 미세 조정을 시작하는 것이 이전 반복의 모델을 기반으로 지속적으로 미세 조정을 진행하는 것보다 더 효과적입니다.
종합해 보면 적은 데이터셋에서 더욱 효과적이었다. 시드데이터에 증강된 데이터를 추가해서 쓰면 더 좋다. 파인튜닝 시작할 때부터 적용해서 튜닝하는 게 더 효과적이다.라고 한다. 직접 써봐야 알 것 같지만 어느 정도 맞을 거 같기도 하다.
5. Conclustion
우리는 수작업으로 데이터를 더 생성하는 대신, 소규모 미세 조정 데이터셋을 확장하기 위해 LLM을 사용하는 적응형 및 반복적 LLM 기반 데이터 증강 프레임워크인 LLM2 LLM을 소개했습니다. 이 프레임워크는 실제 데이터가 필요한 양을 상당히 줄여주며, 수작업으로 데이터를 더 수집하는 효과에 맞먹거나 뛰어넘는 합성 데이터로 데이터셋을 효율적으로 확장할 수 있게 해 줍니다. 이 방법이 효과적인 이유는 프로세스의 반복적이고 타기팅 된 특성 때문이며, 이를 통해 LLM이 잘못한 데이터 포인트에서 신호를 강화할 수 있습니다. 그 결과, LLaMA-2-7B 학생 모델을 사용하여 저 데이터 환경에서 GSM8K에서 24.2%, CaseHOLD에서 32.6%, SNIPS에서 32.9%, TREC에서 57.6%, SST-2 데이터셋에서 39.8%의 개선을 달성했습니다. 향후 연구는 우리 프레임워크의 하이퍼파라미터를 조정하고 프롬프트 튜닝 및 소수샷 학습과 같은 다른 LLM 기술과 접근 방식을 통합하는 데 초점을 맞출 수 있습니다.
Code
# LLM2LLM report_result.py
import json
import re
import os
import argparse
def load_seed_data(seed_data_path):
with open(seed_data_path, 'r') as file:
if seed_data_path.endswith("json"):
return json.load(file)
elif seed_data_path.endswith("jsonl"):
return [json.loads(l) for l in file.readlines()]
else:
raise ValueError("invalid seed data")
# 시드 데이터 내에서 주어진 입력(질문 또는 지시사항)과 일치하는 항목을 찾아 해당 항목의 기대 출력을 반환
def find_matching_seed(seed_data, instruction):
for item in seed_data:
if 'instruction' in item and item['instruction'] == instruction:
return item['output'] # casehold
if 'question' in item and item['question'] == instruction:
return re.search(r'#### (.*)', item['answer'], re.DOTALL)[1]
return None
def clean_string(s):
return ''.join(c for c in s if c.isdigit() or c == '.')
def compare_strings(s1, s2):
try:
num1 = float(clean_string(s1))
num2 = float(clean_string(s2))
return num1 == num2
except:
return s1.lower().replace(",", "") == s2.lower().replace(",", "")
# 평가 폴더 내의 결과 파일들을 순회하며, 각 파일 내의 평가 데이터(모델의 출력)를 시드 데이터와 비교
# 일치하면 Correct_count 를 증가시키고, total_matched 와 correct count 를 비교해서 정확도를 계산
def compare_results(seed_data, eval_folder, results_file_name):
print("Full Path,Correct Count,Total Matched,Accuracy")
for root, dirs, files in os.walk(eval_folder):
files.sort()
dirs.sort()
for file in files:
if file == results_file_name:
full_path = os.path.join(root,file)
with open(full_path, 'r') as file:
eval_data = [json.loads(line) for line in file]
correct_count = 0
total_matched = 0
for eval_item in eval_data:
matching_output = find_matching_seed(seed_data, eval_item['question'])
casehold_output_candidate = re.search(r"Answer:(.*)", eval_item["text"])
gsm_output_candidate = re.search(r"#+ (.*)", eval_item["text"])
if casehold_output_candidate:
casehold_output_candidate = casehold_output_candidate.group(1).strip()
if gsm_output_candidate:
gsm_output_candidate = gsm_output_candidate.group(1).strip()
if matching_output == casehold_output_candidate or (matching_output is not None and gsm_output_candidate is not None and compare_strings(matching_output, gsm_output_candidate)):
correct_count += 1
if matching_output is not None:
total_matched += 1
if total_matched > 0:
accuracy = (correct_count / total_matched) * 100
print(f"{full_path},{correct_count},{total_matched},{accuracy:.2f}")
else:
print(f"{full_path}, No matches found")
def main():
parser = argparse.ArgumentParser(description='Compare output and answer fields in JSON and JSONL files.')
parser.add_argument('seed_data_json', type=str, help='Path to the seed data JSON file')
parser.add_argument('eval_results_folder', type=str, help='Path to the evaluation results folder')
parser.add_argument('--results_file_name', type=str, default="train_0.jsonl", help='Name of the results file (default: train_0.jsonl)')
args = parser.parse_args()
seed_data = load_seed_data(args.seed_data_json)
compare_results(seed_data, args.eval_results_folder, args.results_file_name)
if __name__ == "__main__":
main()



