css 에서 셀렉터 기능이 있다!
javascript로 되어있는 크롤링
당장 우리눈에 보여지는 페이지의 데이터가 아닌 아이프레임이나 자바스크립트 등 다른 URL 로 되어있는 페이지이다.
별도의 URL을 찾아내야 한다!

보통 동적인 기능(스크롤) 이 있으면 JavaScript일 확률이 크다.
* 검사 -> 톱니바퀴 -> 프리퍼런스 -> Debugger -> Disable javascript click -> 리로드
크롤링 할 때 무조건 Javascript인 걸 확인하고 한다.
화면이 뜨지 않는다면. 별도의 URL을 찾는다
별도의 URL 찾는 방법
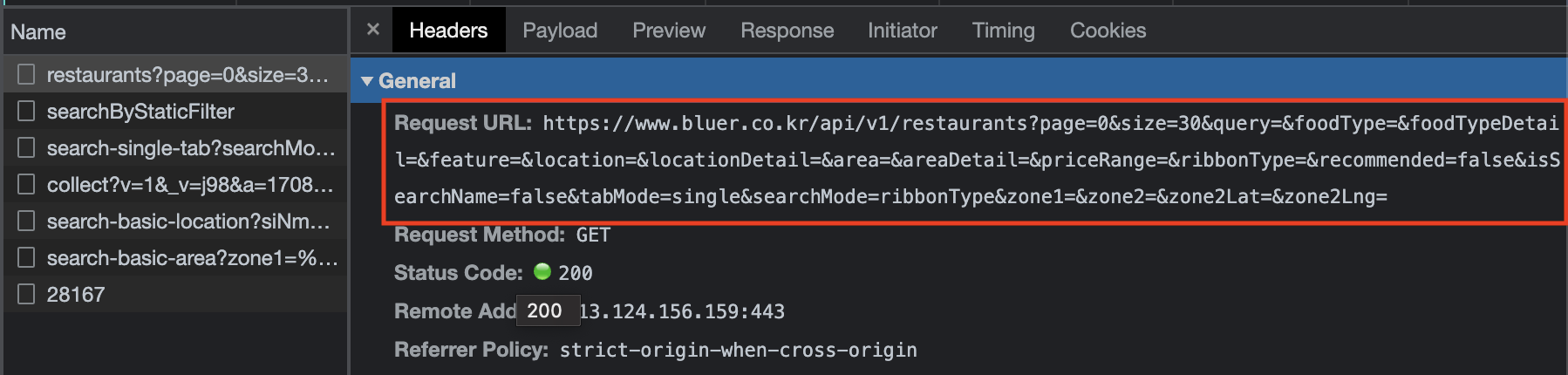
1. javascript disable 이 후 뜨지 않는다면 Elements -> Network 탭으로 변경
2. Tab 에서 Fetch/XHR 탭에 두고,
3. 아래 데이터 목록에서 Preview를 보면서 찾는다.
4. Preview -> 계층 구조 확인 후 -> Header 에서 requests URL 로 크롤링

(서버&클라이언트가 주고 받는 데이터들)




*html 은 태그 계층구조적으로 이루어져있고, JSON은 딕셔너리의 계층구조적으로 이루어져 있다.


***
추가 알아둘 점
클라이언트의 요청 메서드
1) POST : CREATE 2)GET : READ 3) UPDATE : UPDATE 4) DELETE : DELETE (CRED)
크롤링을 하겠다는 것은 read가 맞다.
포스트용으로 의도적으로 짜놓은 경우(페이지를 쓰기 위해서 인경우)
Request Method : GET , 이 부분이 POST 인 경우가 있다.
그럴땐 어떻게 하냐?
requests(url) 이라고 요청을 해야 함
json :
딕셔너리의 텍스트화가 Json 이고 앞뒤로 '''을 붙혀서 텍스트화를 해서 웹상에 배포를 한다.
#dict 로 변환 : import json , json.loads(resp.text) 로즈, 장미 딕셔너리
dic = json.loads(jsn)
#json으로 변환 : json.dumps(dict) 따옴표,dp
jsn= json.dumps(dic)
코딩 실습
'bootcamp' 카테고리의 다른 글
| [데이터 전처리] 전처리란? (0) | 2022.11.01 |
|---|---|
| [웹크롤링] 요청거절당한 동적크롤링 (0) | 2022.10.31 |
| [웹크롤링] 공부방법!? (0) | 2022.10.30 |
| [웹크롤링] 썸네일 이미지 가져오기 (0) | 2022.10.28 |
| [웹크롤링] 실습-2 (0) | 2022.10.28 |
